嵌入模型
Langflow 中的嵌入模型组件使用指定的大语言模型 (LLM) 生成文本嵌入。
Langflow 包含一个核心的 Embedding Model 组件,对某些 LLM 具有内置支持。 或者,您可以使用任何额外的嵌入模型组件来替代核心的 Embedding Model 组件。
内置的 LLM 适用于 Langflow 中大多数基于文本的嵌入模型用例。
在流程中使用嵌入模型组件
在流程中任何需要生成嵌入的地方使用嵌入模型组件。
此示例展示了如何在流程中使用嵌入模型组件创建语义搜索系统。 此流程加载文本文件,将文本分割成块,为每个块生成嵌入,然后将块和嵌入加载到向量存储中。输入和输出组件允许用户通过聊天界面查询向量存储。
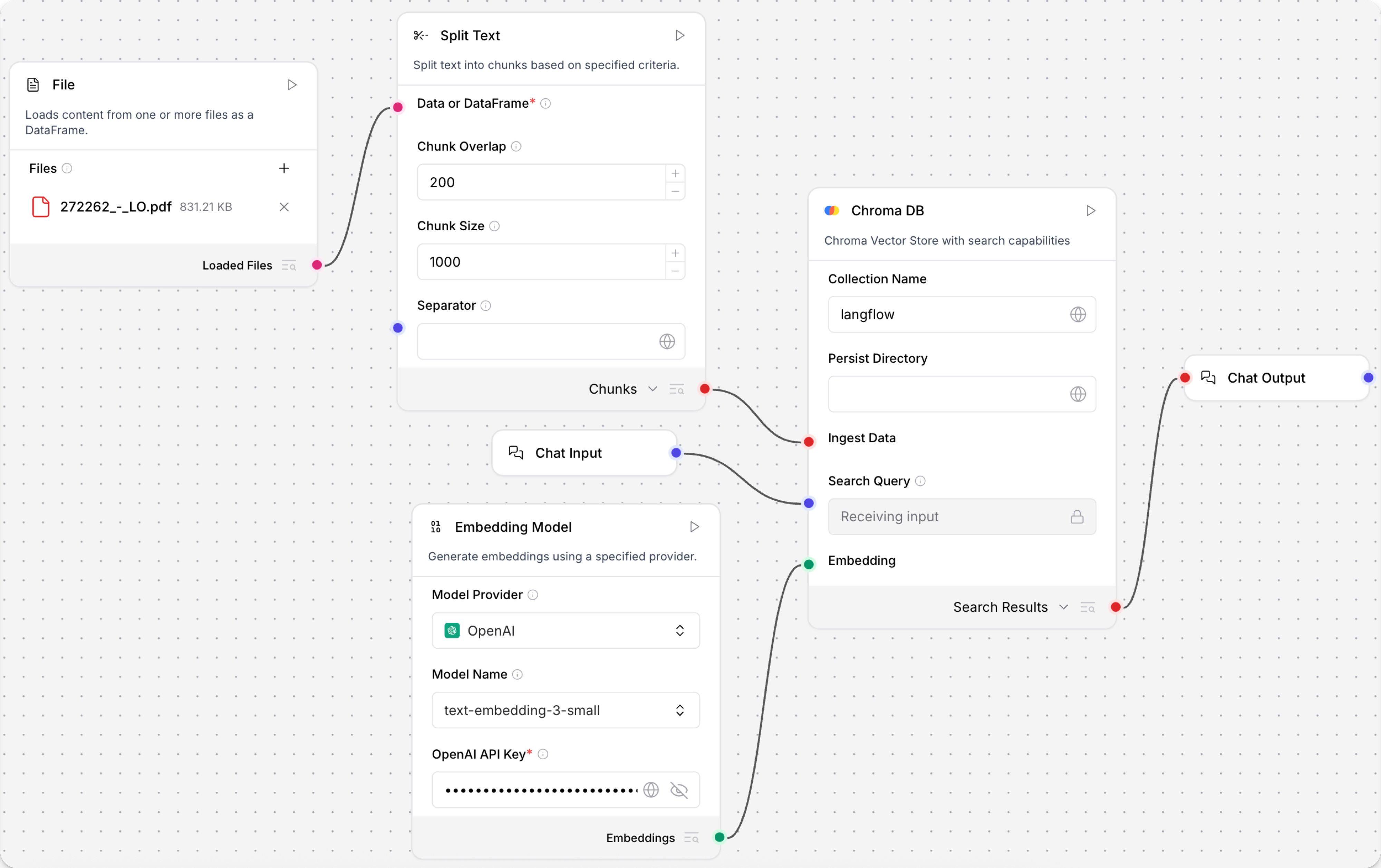
此示例使用核心的 Embedding Model 组件。
要使用其他模型,您可以在这些步骤中将核心的 Embedding Model 组件替换为任何额外的嵌入模型组件。 但是,您的组件可能具有与核心 Embedding Model 组件略有不同的参数。
-
创建一个流程,添加一个 File 组件,然后选择一个包含文本数据的文件(如 PDF),您可以使用它来测试流程。
-
添加一个 Embedding Model 组件,然后提供有效的 OpenAI API 密钥。
默认情况下,Embedding Model 组件使用 OpenAI 模型。 如果您想使用不同的模型,请相应地编辑 Model Name 和 API Key 字段。 或者,请参阅额外的嵌入模型组件以了解可以用来替代核心 Embedding Model 组件的其他嵌入模型组件。
您可以直接输入组件 API 密钥或使用 Langflow 全局变量来引用您的 API 密钥。
-
向您的流程添加一个 Split Text 组件。 此组件将文本输入分割成更小的块以处理成嵌入。
-
向您的流程添加一个Vector Store 组件,如 Chroma DB 组件,然后配置组件以连接到您的向量存储数据库。 此组件存储生成的嵌入,以便它们可以用于相似性搜索。
-
连接组件:
- 将 File 组件的 Loaded Files 输出连接到 Split Text 组件的 Data or DataFrame 输入。
- 将 Split Text 组件的 Chunks 输出连接到 Vector Store 组件的 Ingest Data 输入。
- 将 Embedding Model 组件的 Embeddings 输出连接到 Vector Store 组件的 Embedding 输入。
-
要查询向量存储,添加 Chat Input/Output 组件:
- 将 Chat Input 组件连接到 Vector Store 组件的 Search Query 输入。
- 将 Vector Store 组件的 Search Results 输出连接到 Chat Output 组件。
-
单击 Playground,然后输入搜索查询以检索与您的查询在语义上最相似的文本块。
Embedding Model
Embedding Model 组件的一些输入参数在可视化编辑器中默认隐藏。 您可以通过组件标题菜单中的 Controls 切换参数。
| 名称 | 显示名称 | 类型 | 描述 |
|---|---|---|---|
| provider | Model Provider | List | 输入参数。选择嵌入模型提供商。 |
| model | Model Name | List | 输入参数。选择要使用的嵌入模型。 |
| api_key | OpenAI API Key | Secret[String] | 输入参数。与提供商进行身份验证所需的 API 密钥。 |
| api_base | API Base URL | String | 输入参数。API 的基础 URL。留空为默认值。 |
| dimensions | Dimensions | Integer | 输入�参数。输出嵌入的维数。 |
| chunk_size | Chunk Size | Integer | 输入参数。要处理的文本块的大小。默认:1000。 |
| request_timeout | Request Timeout | Float | 输入参数。API 请求的超时时间。 |
| max_retries | Max Retries | Integer | 输入参数。最大重试尝试次数。默认:3。 |
| show_progress_bar | Show Progress Bar | Boolean | 输入参数。是否在嵌入生成过程中显示进度条。 |
| model_kwargs | Model Kwargs | Dictionary | 输入参数。传递给模型的其他关键字参数。 |
| embeddings | Embeddings | Embeddings | 输出参数。使用所选提供商生成嵌入的实例。 |
额外的嵌入模型组件
如果核心 Embedding Model 组件不支持您的提供商或模型,Components 菜单的 Bundles 部分提供了额外的单一提供商嵌入模型组件。
遗留嵌入组件
以下组件是遗留组件。 您仍然可以在流程中使用它们,但它们不再维护,可能会在未来版本中被移除。
Embedding Similarity
Embedding Similarity 组件�被 Vector Store 组件中的内置相似性搜索功能所取代。
此组件计算两个嵌入向量的相似性分数。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_vectors | Embedding Vectors | 输入参数。包含恰好两个要比较的带有嵌入向量的数据对象的列表。 |
| similarity_metric | Similarity Metric | 输入参数。选择要使用的相似性度量。选项:"Cosine Similarity"、"Euclidean Distance"、"Manhattan Distance"。 |
| similarity_data | Similarity Data | 输出参数。包含计算出的相似性分数和其他信息的数据对象。 |
Text Embedder
Text Embedder 组件被 Embedding Model 组件所取代。
此组件使用指定的嵌入模型为给定消息生成嵌入。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_model | Embedding Model | 输入参数。用于生成嵌入的嵌入模型。 |
| message | Message | 输入参数。要为其生成嵌入的消息。 |
| embeddings | Embedding Data | 输出参数。包含原始文本及其嵌入向量的数据对象。 |