处理组件
Langflow的处理组件在流程中处理和转换数据。 它们有很多用途,包括:
- 使用Prompt Template组件为你的LLM和智能体提供指令和上下文。
- 使用Parser组件从大块数据中提取内容。
- 使用Smart Function组件通过自然语言过滤数据。
- 使用Save File组件将数据保存到本地机器。
- 使用Type Convert组件将数据转换为不同的数据类型,以便在不兼容的组件之间传递。
Prompt Template
参见 Prompt Template。
Batch Run
Batch Run组件在DataFrame的_每行单个文本列_上运行语言模型,然后返回一个包含原始文本和LLM响应的新DataFrame。
响应包含以下列:
text_input:来自输入DataFrame的原始文本model_response:每个输入的模型响应batch_index:DataFrame中所有行的0索引处理顺序metadata(可选):关于处理的附加信息
在流程中使用Batch Run组件
如果你将此输出传递给Parser组件,你可以在解析模板中使用变量来引用这些键,例如{text_input}和{model_response}。
以下示例演示了这一点。
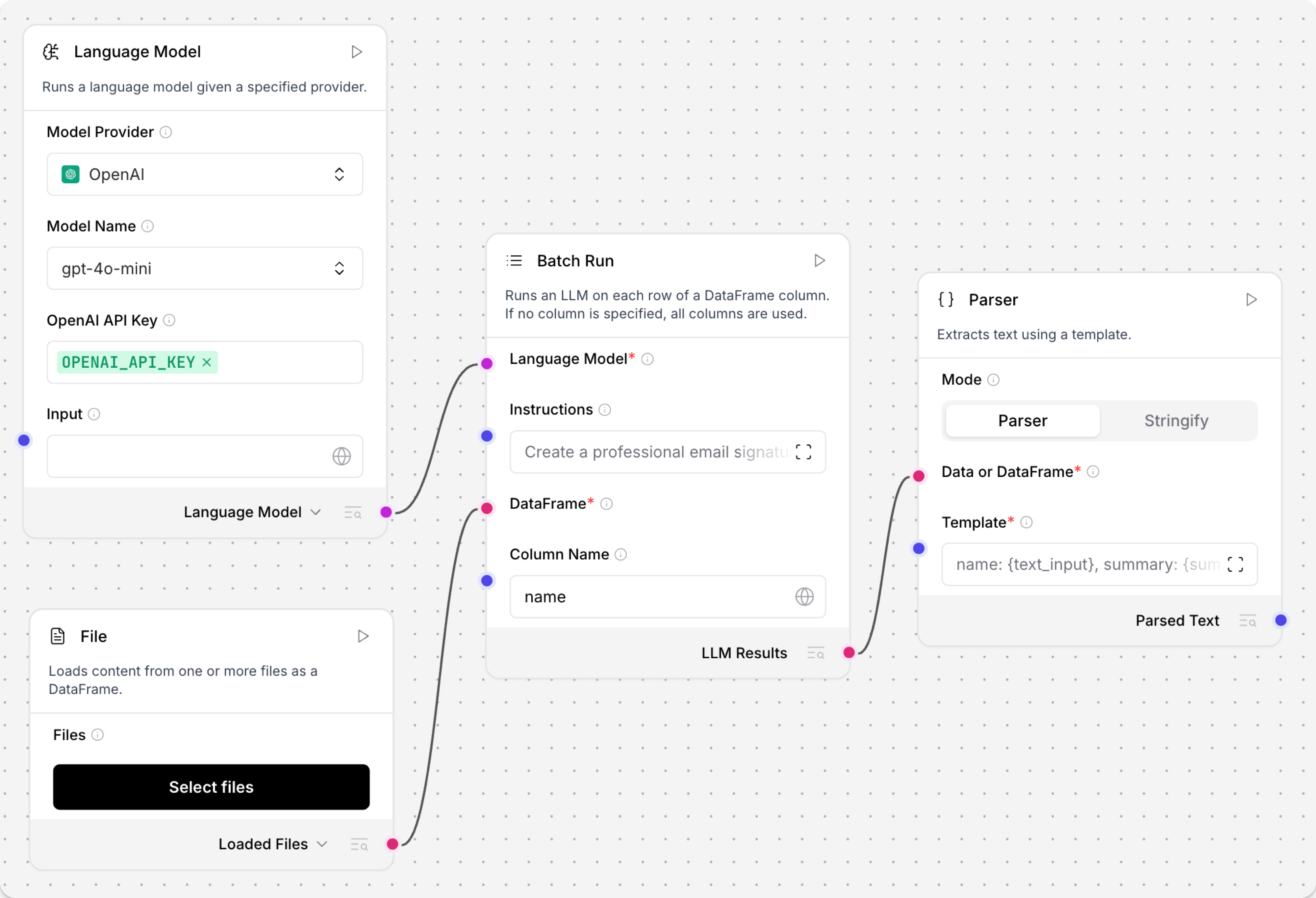
-
将Language Model组件连接到Batch Run组件的Language model端口。
-
将另一个组件的
DataFrame输出连接到Batch Run组件的DataFrame输入。 例如,你可以连接一个带有CSV文件的File组件。 -
在Batch Run组件的Column Name字段中,输入传入
DataFrame中包含要处理文本的列名。 例如,如果你想从CSV文件的name列中提取文本,在Column Name字段中输入name。 -
将Batch Run组件的Batch Results输出连接到Parser组件的DataFrame输入。
-
可选:在Batch Run组件的标题菜单中,点击 Controls,启用System Message参数,点击Close,然后输入你希望LLM如何处理从文件中提取的每个单元格的指令。 例如,
为每个姓名创建一张名片。 -
在Parser组件的Template字段中,输入用于处理Batch Run组件新
DataFrame列(text_input、model_response和batch_index)的模板:例如,此模板使用结果后批处理
DataFrame中的三列:_10record_number: {batch_index}, name: {text_input}, summary: {model_response} -
要测试处理,点击Parser组件,然后点击 Run component,然后点击 Inspect output查看最终的
DataFrame。如果你想在Playground中看到输出,你也可以将Chat Output组件连接到Parser组件。
Batch Run参数
一些Batch Run组件输入参数在视觉编辑器中默认隐藏。 你可以通过组件标题菜单中的 Controls切换参数。
| 名称 | 类型 | 描述 |
|---|---|---|
| model | HandleInput | 输入参数。在此连接LLM组件的'Language Model'输出。必需。 |
| system_message | MultilineInput | 输入参数。DataFrame中所有行的多行系统指令。 |
| df | DataFrameInput | 输入参数。其列被视为文本消息的DataFrame,由'column_name'指定。必需。 |
| column_name | MessageTextInput | 输入参数。被视为文本消息的DataFrame列名。如果为空,所有列都格式化为TOML。 |
| output_column_name | MessageTextInput | 输入参数。存储模型响应的列名。�默认=model_response。 |
| enable_metadata | BoolInput | 输入参数。如果为True,向输出DataFrame添加元数据。 |
| batch_results | DataFrame | 输出参数。包含所有原始列加上模型响应列的DataFrame。 |
Data Operations
Data Operations组件对Data对象执行操作,包括选择键、评估字面量、组合数据、过滤值、追加/更新数据、删除键和重命名键。
-
要在流程中使用Data Operations组件,你必须将其Data输入端口连接到输出
Data的组件的输出端口。 Data Operations组件中的所有操作都需要至少一个Data输入。对于此示例,向流程添加一个Webhook组件,然后将其连接到Data Operations组件。假设你将向webhook发送具有一致有效载荷的请求,该有效载荷具有
name、username和email键。 -
在Operations字段中,选择你想在传入
Data上执行的操作。 对于此示例,选择Select Keys操作来提取特定的用户信息。 -
添加
name、username和email键以从传入的请求有效载荷中选择这些值。要添加更多键,点击 Add more。
-
连接Chat Output组件。
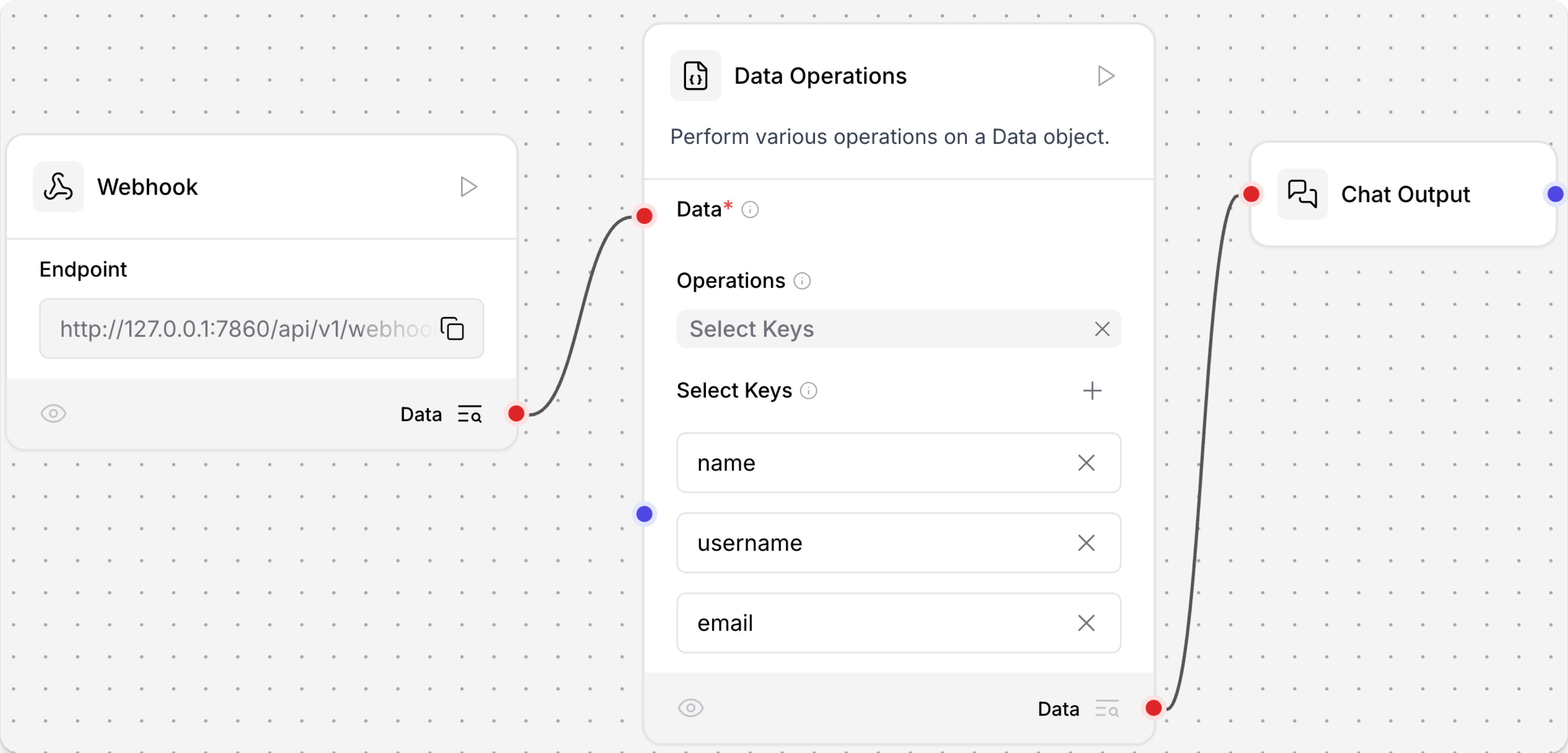
-
要测试流程,向你的流程webhook端点发送以下请求,然后打开Playground查看处理有效载荷的结果输出。
_26curl -X POST "http://$LANGFLOW_SERVER_URL/api/v1/webhook/$FLOW_ID" \_26-H "Content-Type: application/json" \_26-H "x-api-key: $LANGFLOW_API_KEY" \_26-d '{_26"id": 1,_26"name": "Leanne Graham",_26"username": "Bret",_26"email": "Sincere@april.biz",_26"address": {_26"street": "Main Street",_26"suite": "Apt. 556",_26"city": "Springfield",_26"zipcode": "92998-3874",_26"geo": {_26"lat": "-37.3159",_26"lng": "81.1496"_26}_26},_26"phone": "1-770-736-8031 x56442",_26"website": "hildegard.org",_26"company": {_26"name": "Acme-Corp",_26"catchPhrase": "Multi-layered client-server neural-net",_26"bs": "harness real-time e-markets"_26}_26}'
Data Operations参数
一些Data Operations组件输入参数在视觉编辑器中默认隐藏。 你可以通过组件标题菜单中的 Controls切换参数。
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | Data | 输入参数。要操作的Data对象。 |
| operations | Operations | 输入参数。对数据执行的操作。参见Data Operations operations |
| select_keys_input | Select Keys | 输入参数。要从数据中选择的键列表。 |
| filter_key | Filter Key | 输入参数。要过滤的键。 |
| operator | Comparison Operator | 输入参数。用于比较值的运算符。 |
| filter_values | Filter Values | 输入参数。要过滤的值列表。 |
| append_update_data | Append or Update | 输入参数。要追加或更新现有数据的数据。 |
| remove_keys_input | Remove Keys | 输入参数。要从数据中删除的键列表。 |
| rename_keys_input | Rename Keys | 输入参数。要在数据中重命名的键列表。 |
| data_output | Data | 输出参数。操作后的结果Data对象。 |
Data Operations操作
operations输入参数的选项如下。
所有操作都作用于传入的Data对象。
| 名称 | 必需输入 | 处理 |
|---|---|---|
| Select Keys | select_keys_input | 从数据中选择特定键。 |
| Literal Eval | None | 将字符串值评估为Python字面量。 |
| Combine | None | 将多个数据对象合并为一个。 |
| Filter Values | filter_key, filter_values, operator | 基于键值对过滤数据。 |
| Append or Update | append_update_data | 添加或更新键值对。 |
| Remove Keys | remove_keys_input | 从数据中删除指定的键。 |
| Rename Keys | rename_keys_input | 重命名数据中的键。 |
DataFrame operations
DataFrame组件对DataFrame行和列执行操作。
要在流程中使用DataFrame Operations组件,你必须将其DataFrame输入端口连接到输出DataFrame的组件的输出端口。
DataFrame Operations组件中的所有操作都需要至少一个DataFrame输入。
以下示例从API获取JSON数据。Smart Filter组件提取并扁平化结果为表格DataFrame,然后通过DataFrame Operations组件处理。
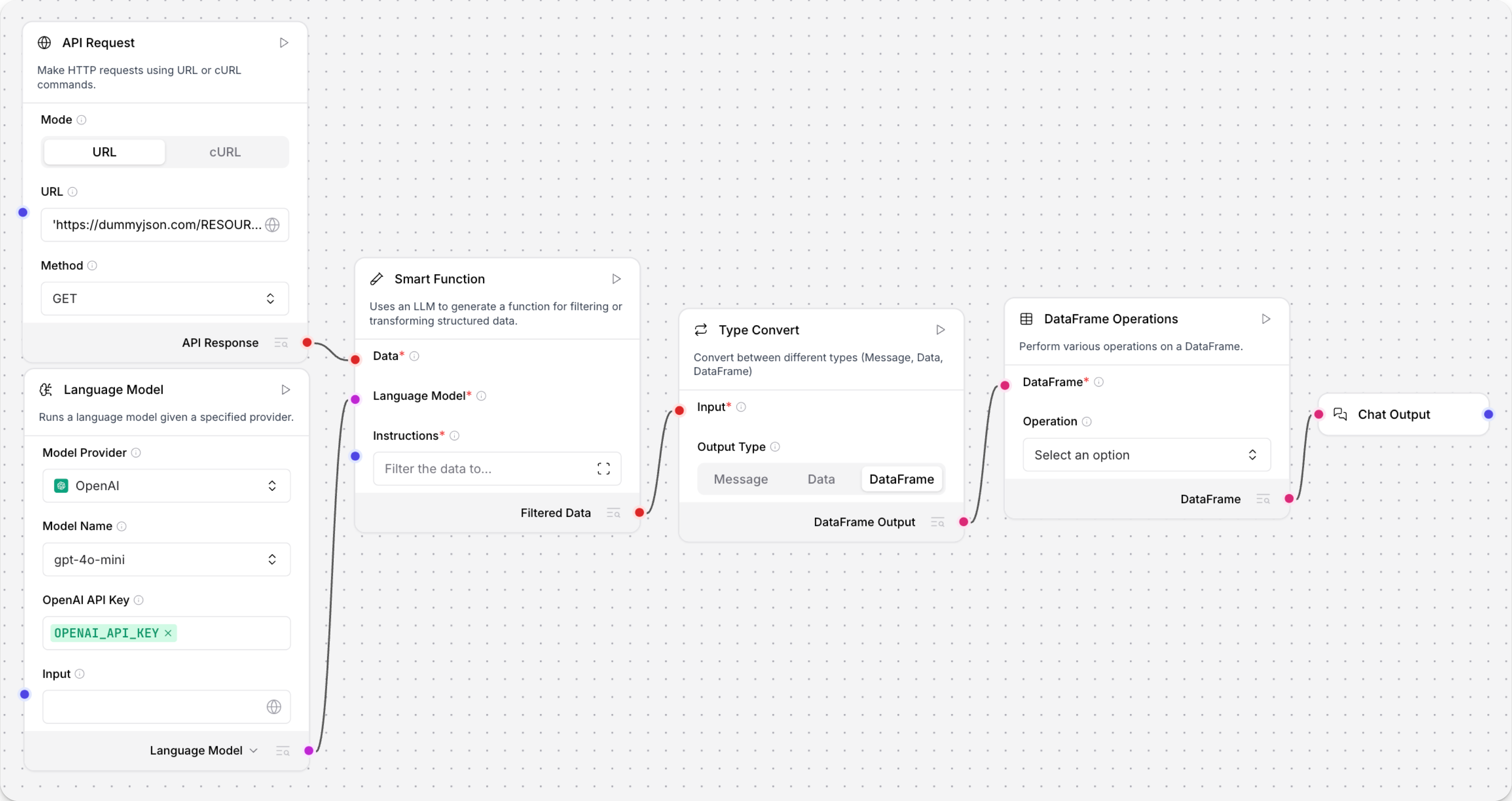
- API Request组件只检索具有
source和result字段的数据。 对于此示例,所需数据嵌套在result字��段中。 - 将Smart Filter连接到API请求组件,将Language model连接到Smart Filter。此示例连接Groq模型组件。
- 在Groq模型组件中,添加你的Groq API密钥。
- 要过滤数据,在Smart filter组件的Instructions字段中,使用自然语言描述如何过滤数据。 对于此示例,输入:
_10I want to explode the result column out into a Data object
避免在Instructions字段中使用标点符号,因为它可能导致错误。
- 要运行流程,在Smart Filter组件中,点击 Run component。
- 要检查过滤的数据,在Smart Filter组件中,点击 Inspect output。 结果是一个结构化DataFrame。
_10id | name | company | username | email | address | zip_10---|------------------|----------------------|-----------------|------------------------------------|-------------------|-------_101 | Emily Johnson | ABC Corporation | emily_johnson | emily.johnson@abccorporation.com | 123 Main St | 12345_102 | Michael Williams | XYZ Corp | michael_williams| michael.williams@xyzcorp.com | 456 Elm Ave | 67890
- 添加DataFrame Operations组件和Chat Output组件到流程。
- 在DataFrame Operations组��件的Operation字段中,选择Filter。
- 要应用过滤器,在Column Name字段中,输入要过滤的列。此示例按
name过滤。 - 点击Playground,然后点击Run Flow。
流程从
name列中提取值。
_10name_10Emily Johnson_10Michael Williams_10John Smith_10...
操作
此组件可以对Pandas DataFrame执行以下操作。
| 操作 | 必需输入 | 信息 |
|---|---|---|
| Add Column | new_column_name, new_column_value | 添加具有常量值的新列。 |
| Drop Column | column_name | 删除指定列。 |
| Filter | column_name, filter_value | 基于列值过滤行。 |
| Head | num_rows | 返回前n行。 |
| Rename Column | column_name, new_column_name | 重命名现有列。 |
| Replace Value | column_name, replace_value, replacement_value | 替换列中的值。 |
| Select Columns | columns_to_select | 选择特定列。 |
| Sort | column_name, ascending | 按列排序DataFrame。 |
| Tail | num_rows | 返回最后n行。 |
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| df | DataFrame | 要操作的输入DataFrame。 |
| operation | Operation | 要执行的DataFrame操作。选项包括Add Column、Drop Column、Filter、Head、Rename Column、Replace Value、Select Columns、Sort和Tail。 |
| column_name | Column Name | 用于操作的列名。 |
| filter_value | Filter Value | 过滤行的值。 |
| ascending | Sort Ascending | 是否按升序排序。 |
| new_column_name | New Column Name | 重命名或添加列时的新列名。 |
| new_column_value | New Column Value | 填充新列的值。 |
| columns_to_select | Columns to Select | 要选择的列名列表。 |
| num_rows | Number of Rows | head/tail操作要返回的行数。默认为5。 |
| replace_value | Value to Replace | 要在列中替换的值。 |
| replacement_value | Replacement Value | 要替换为的值。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | DataFrame | 操作后的结果DataFrame。 |
LLM router
此组件基于OpenRouter模型规范将请求路由到最合适的LLM。
判断LLM分析你的输入消息以理解评估上下文,然后从你的LLM池中选择最合适的模型。
选定的模型处理你的输入并返回响应。
要在流程中使用LLM Router组件,请执行以下操作:
-
将多个Language Model组件连接到LLM Router的Language Models输入。
-
将Judge LLM组件连接到Judge LLM输入。
-
将Chat Input和Chat Output组件连接到LLM Router。 流程如下所示:
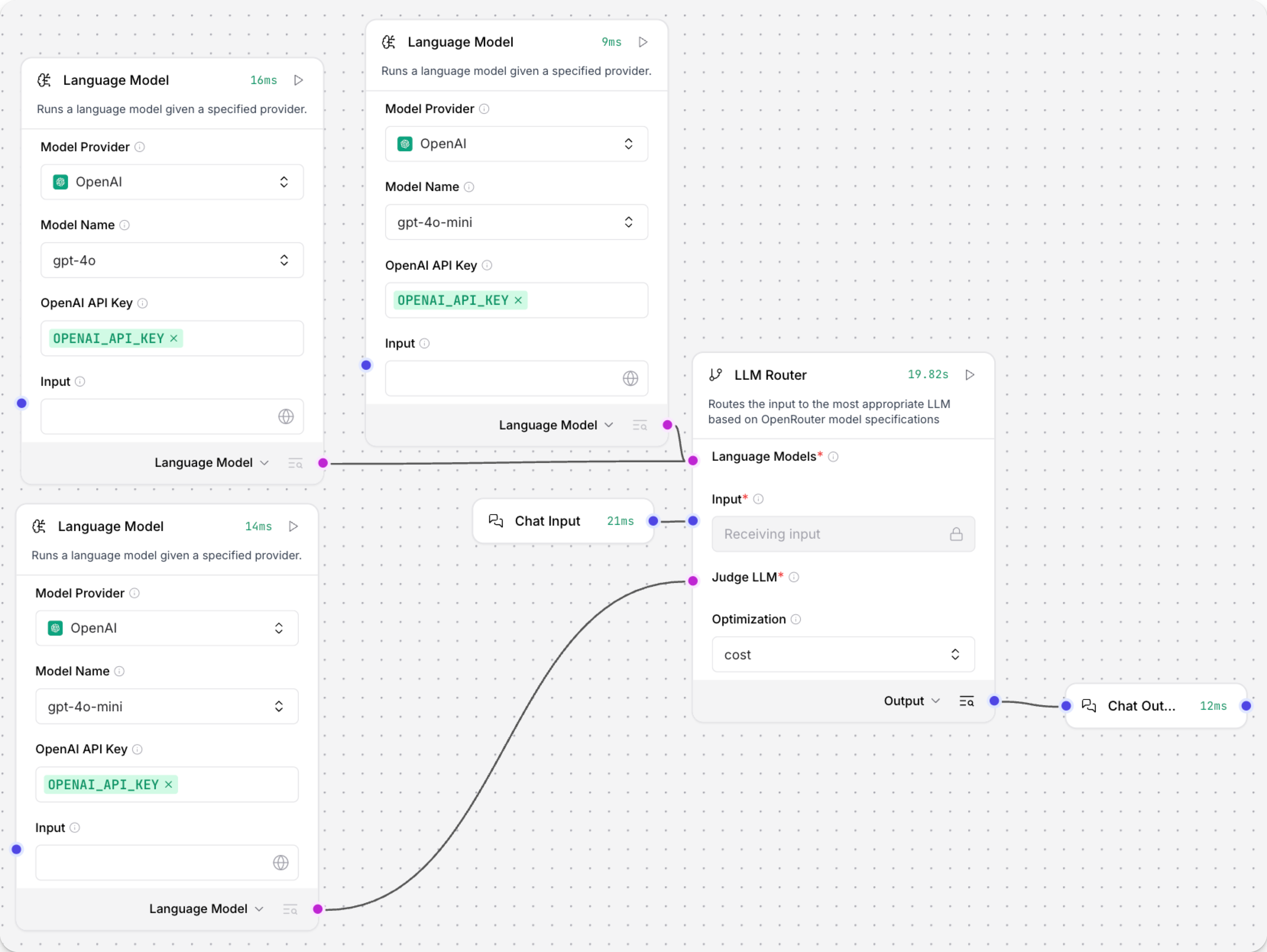
-
在LLM Router组件中,设置你的Optimization偏好:
- Quality:优先考虑最高质量的响应。
- Speed:优先考虑最快的响应时间。
- Cost:优先考虑最具成本效益的选项。
- Balanced:在质量、速度和成本之间取得平衡。
-
运行流程。 你的输入是LLM路由器用来评估模型的任务,例如
写一个关于马的故事或如何从JSON中解析数据对象?。 -
在LLM Router组件中,选择Model Selection Decision输出查看路由�器的推理。
_10Model Selection Decision:_10- Selected Model Index: 0_10- Selected Langflow Model Name: gpt-4o-mini_10- Selected API Model ID (if resolved): openai/gpt-4o-mini_10- Optimization Preference: cost_10- Input Query Length: 27 characters (~5 tokens)_10- Number of Models Considered: 2_10- Specifications Source: OpenRouter API
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| models | Language Models | 要路由的LLM列表。 |
| input_value | Input | 要路由的输入消息。 |
| judge_llm | Judge LLM | 评估并选择最合适模型的LLM。 |
| optimization | Optimization | 质量、速度、成本或平衡之间的优化偏好。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | Output | 选定模型的响应。 |
| selected_model | Selected Model | 选择的模型名称。 |
Parser
此组件使用模板将DataFrame或Data对象格式化为文本,并可选择使用stringify直接将输入转换为字符串。
要使用此组件,在template中为值创建变量的方式与在Prompt组件中相同。对于DataFrames,使用列名,例如Name: {Name}。对于Data对象,使用{text}。
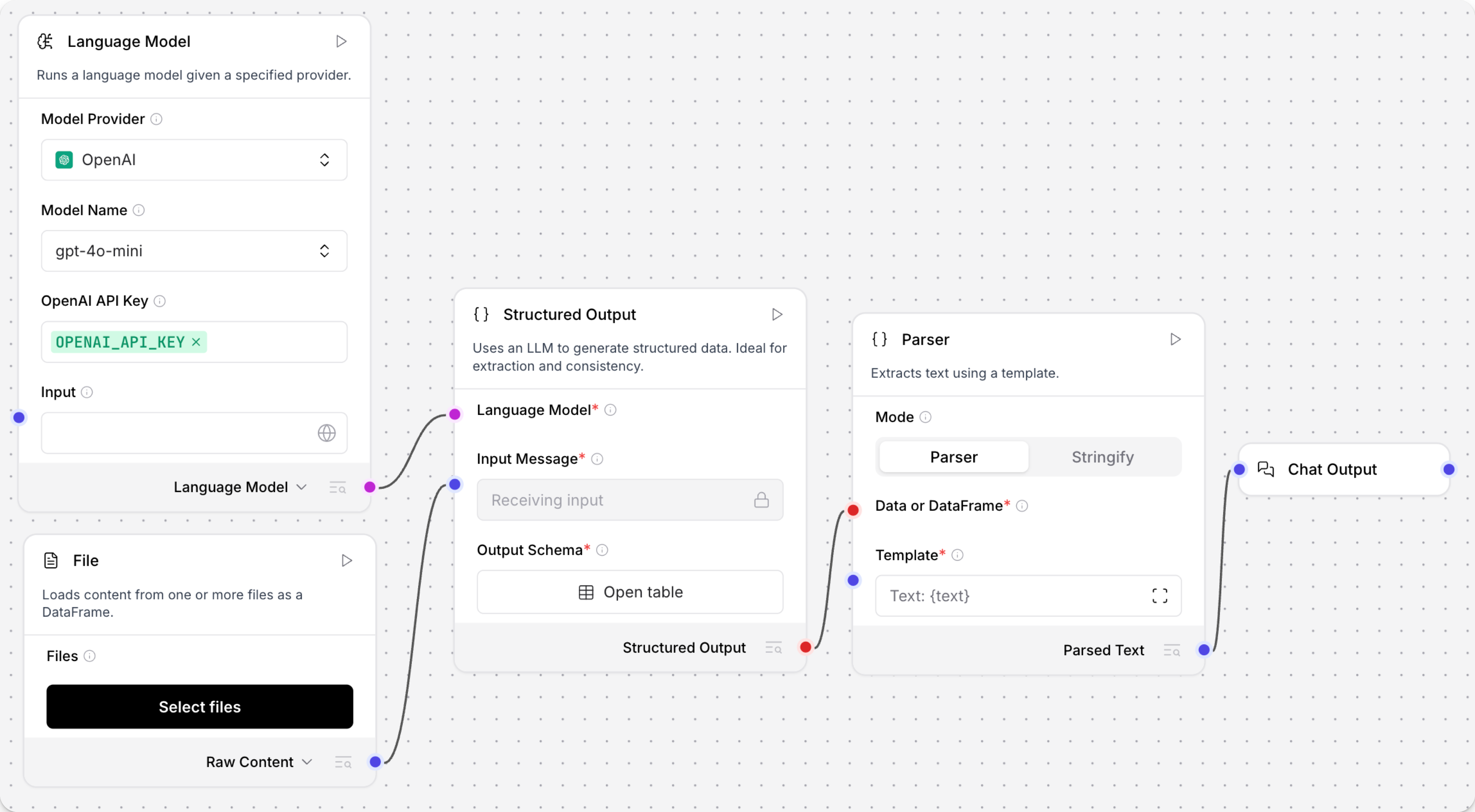
要将Parser组件与Structured Output组件一起使用,请执行以下操作:
- 将Structured Output组件的DataFrame输出连接到Parser组件的DataFrame输入。
- 将File组件连接到Structured Output组件的Message输入。
- 将OpenAI模型组件的Language Model输出连接到Structured Output组件的Language Model输入。
流程如下所示:
- 在Structured Output组件中,点击Open Table。 这将打开一个用于构建表格的面板。 表格包含行Name、Description、Type和Multiple。
- 创建一个映射到你从File加载器加载的数据的表格。
例如,要为员工创建表格,你可能有行
id、name和email,所有类型都是string。 - 在Parser组件的Template字段中,输入用于将Structured Output组件的DataFrame输出解析为结构化文本的模板。
在
template中为值创建变量的方式与在Prompt组件中相同。 例如,要在Markdown中展示员工表格:
_10# Employee Profile_10## Personal Information_10- **Name:** {name}_10- **ID:** {id}_10- **Email:** {email}
- 要运行流程,在Parser组件中,点击 Run component。
- 要查看你的解析文本,在Parser组件中,点击 Inspect output。
- 可选地,连接Chat Output组件,并打开Playground查看输出。
关于使用Parser组件格式化来自Structured Output组件的DataFrame的另一个示例,请参见Market Research模板流程。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| mode | Mode | "Parser"和"Stringify"模式之间的选项卡选择。"Stringify"将输入转换为字符串而不是使用模板。 |
| pattern | Template | 使用大括号中的变量进行格式化的模板。对于DataFrames,使用列名,例如Name: {Name}。对于Data对象,使用{text}。 |
| input_data | Data or DataFrame | 要解析的输入。接受DataFrame或Data对象。 |
| sep | Separator | 用于分隔行或项目的字符串。默认为换行符。 |
| clean_data | Clean Data | 当启用stringify时,此选项通过删除空行和行来清理数据。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| parsed_text | Parsed Text | 作为Message对象的结果格式化文本。 |
Python Interpreter
此组件允许你使用导入的包执行Python代码。
在流程中使用Python Interpreter
- 要在流程中使用此组件,在Global Imports字段中,添加你想要导入的包作为逗号分隔列表,例如
math,pandas。 至少需要一个导入。 - 在Python Code字段中,输入你想要执行的Python代码。使用
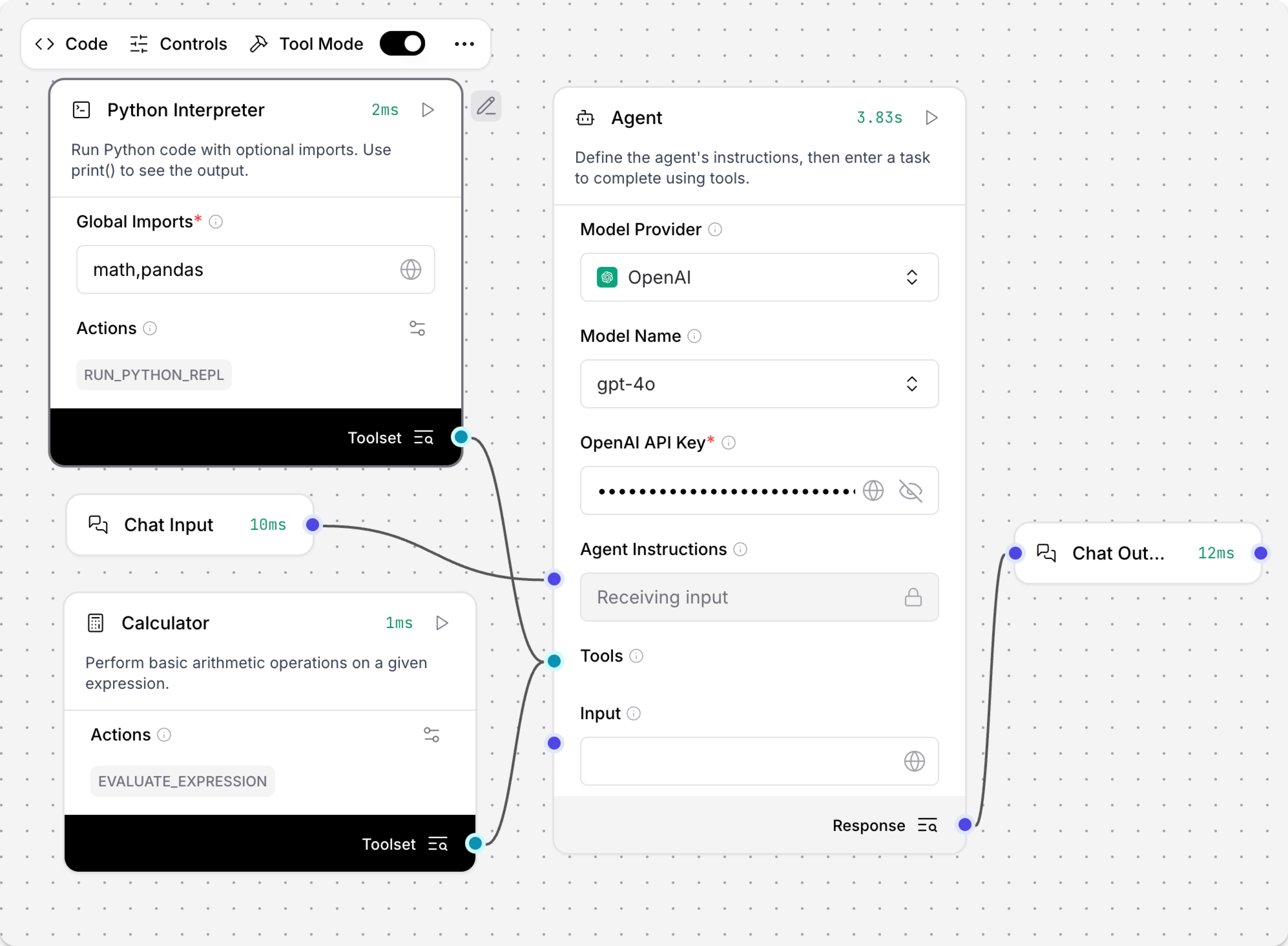
print()查看输出。 - 可选地,启用Tool Mode并将解释器连接到Agent作为工具。
例如,将Python Interpreter和Calculator作为Agent的工具连接,并测试它如何选择不同的工具来解决数学问题。
流程如下所示:
- 向智能体询问一个简单的数学问题。
Calculator工具可以加、减、乘、除或执行指数运算。
智能体执行
evaluate_expression工具来正确回答问题。
结果:
_10Executed evaluate_expression_10Input:_10{_10 "expression": "2+5"_10}_10Output:_10{_10 "result": "7"_10}
- 给智能体完整的Python代码。
此示例使用导入的
pandas包创建Pandas DataFrame表格,并返回均方的平方根。
_12import pandas as pd_12import math_12_12# Create a simple DataFrame_12df = pd.DataFrame({_12 'numbers': [1, 2, 3, 4, 5],_12 'squares': [x**2 for x in range(1, 6)]_12})_12_12# Calculate the square root of the mean_12result = math.sqrt(df['squares'].mean())_12print(f"Square root of mean squares: {result}")
Agent正确选择run_python_repl工具来解决问题。
结果:
_12Executed run_python_repl_12_12Input:_12_12{_12 "python_code": "import pandas as pd\nimport math\n\n# Create a simple DataFrame\ndf = pd.DataFrame({\n 'numbers': [1, 2, 3, 4, 5],\n 'squares': [x**2 for x in range(1, 6)]\n})\n\n# Calculate the square root of the mean\nresult = math.sqrt(df['squares'].mean())\nprint(f\"Square root of mean squares: {result}\")"_12}_12Output:_12_12{_12 "result": "Square root of mean squares: 3.3166247903554"_12}
如果你在聊天中不包含包导入,Agent仍然可以使用pd.DataFrame创建表格,因为pandas包在Python解释器组件的Global Imports字段中全局导入。
Python Interpreter参数
| 名称 | 类型 | 描述 |
|---|---|---|
| global_imports | String | 输入参数。要全局导入的模块的逗号分隔列表,例如math,pandas,numpy。 |
| python_code | Code | 输入参数。要执行的Python代码。只能使用在Global Imports中指定的模块。 |
| results | Data | 输出参数。执行的Python代码的输出,包括任何打印结果或错误。 |
Save file
此组件将DataFrames、Data或Messages保存为各种文件格式。
- 要在流程中使用此组件,将输出DataFrames、Data或Messages的组件连接到Save to File组件的输入。 以下示例将Webhook组件连接到两个Save to File组件以演示不同的输出。
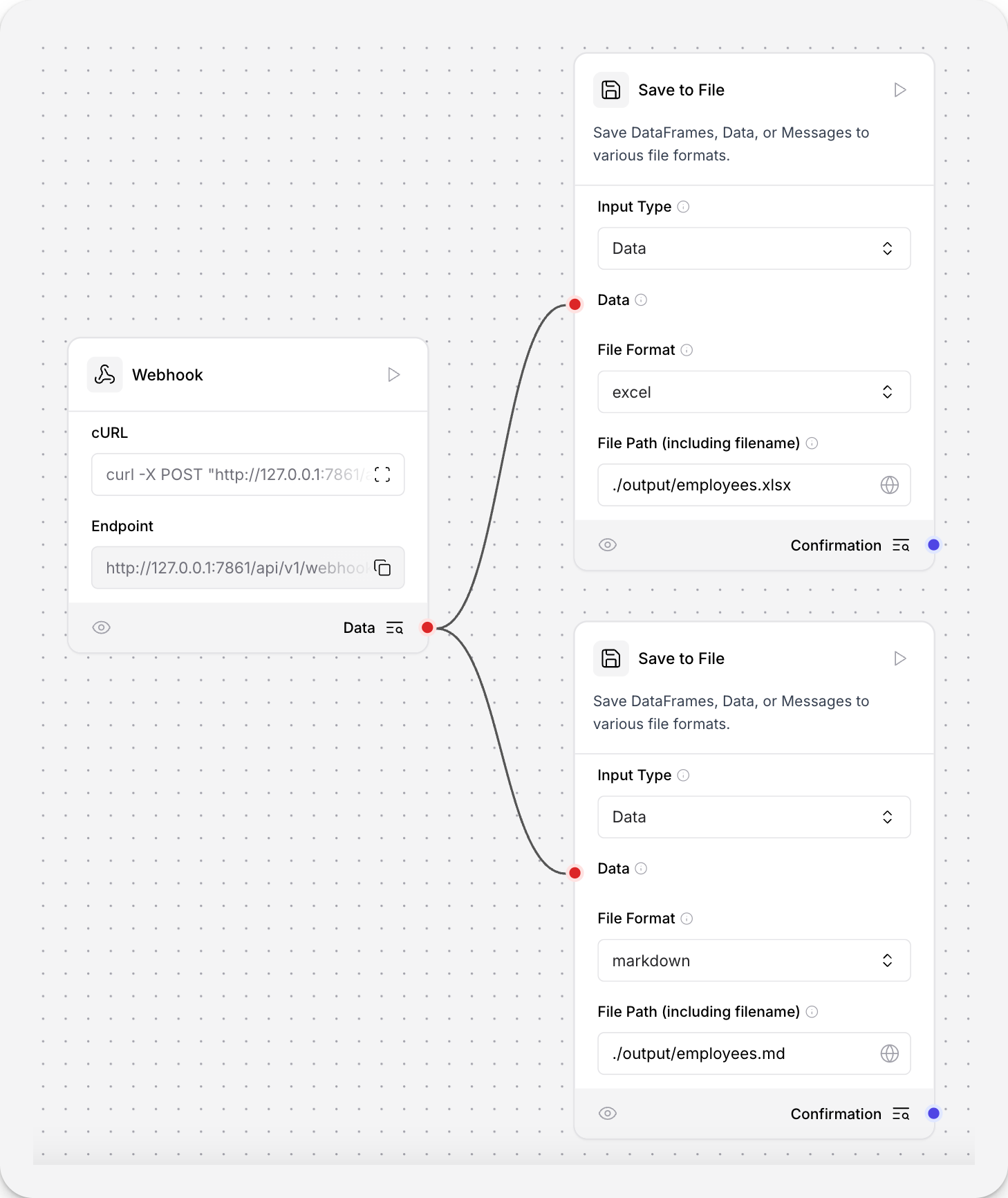
- 在Save to File组件的Input Type字段中,选择预期的输入类�型。 此示例期望来自Webhook的Data。
- 在File Format字段中,选择保存文件的文件类型。
此示例在一个Save to File组件中使用
.md,在另一个中使用.xlsx。 - 在File Path字段中,输入保存文件的路径。
此示例使用
./output/employees.xlsx和./output/employees.md将文件保存到相对于Langflow运行位置的目录中。 组件接受相对和绝对路径,如果目录不存在则创建任何必要的目录。
如果你输入的file_path格式不被接受,组件会将适当的格式附加到文件中。
例如,如果选择的file_format是csv,你输入的file_path是./output/test.txt,文件将保存为./output/test.txt.csv,以便文件不被损坏。
- 向包含你的JSON数据的Webhook发送POST请求。
将
YOUR_FLOW_ID替换为你的流程ID。 此示例使用默认的Langflow服务器地址。
_10curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \_10-H 'Content-Type: application/json' \_10-H 'x-api-key: LANGFLOW_API_KEY' \_10-d '{_10 "Name": ["Alex Cruz", "Kalani Smith", "Noam Johnson"],_10 "Role": ["Developer", "Designer", "Manager"],_10 "Department": ["Engineering", "Design", "Management"]_10}'
- 在你的本地文件系统中,打开
outputs目录。 你应该看到从你发送的数据创建的两个文件:一个.xlsx用于结构化电子表格,一个Markdown。
_10| Name | Role | Department |_10|:-------------|:----------|:-------------|_10| Alex Cruz | Developer | Engineering |_10| Kalani Smith | Designer | Design |_10| Noam Johnson | Manager | Management |
文件输入格式选项
对于DataFrame和Data输入,组件可以创建:
csvexceljsonmarkdownpdf
对于Message输入,组件可以创建:
txtjsonmarkdownpdf
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_text | Input Text | 要分析和从中提取模式的文本。 |
| pattern | Regex Pattern | 要在文本中匹配的正则表达式模式。 |
| input_type | Input Type | 要保存的输入类型。 |
| df | DataFrame | 要保存的DataFrame。 |
| data | Data | 要保存的Data对象。 |
| message | Message | 要保存的Message。 |
| file_format | File Format | 保存输入的文件格式。 |
| file_path | File Path | 包括文件名和扩展名的完整文件路径。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | Data | 作为Data对象的提取匹配列表。 |
| text | Message | 格式化为Message对象的提取匹配。 |
| confirmation | Confirmation | 保存文件后的确认消息。 |
Smart function
在Langflow 1.5之前,此组件被命名为Lambda filter。
此组件使用LLM生成用于过滤或转换结构化数据的函数。
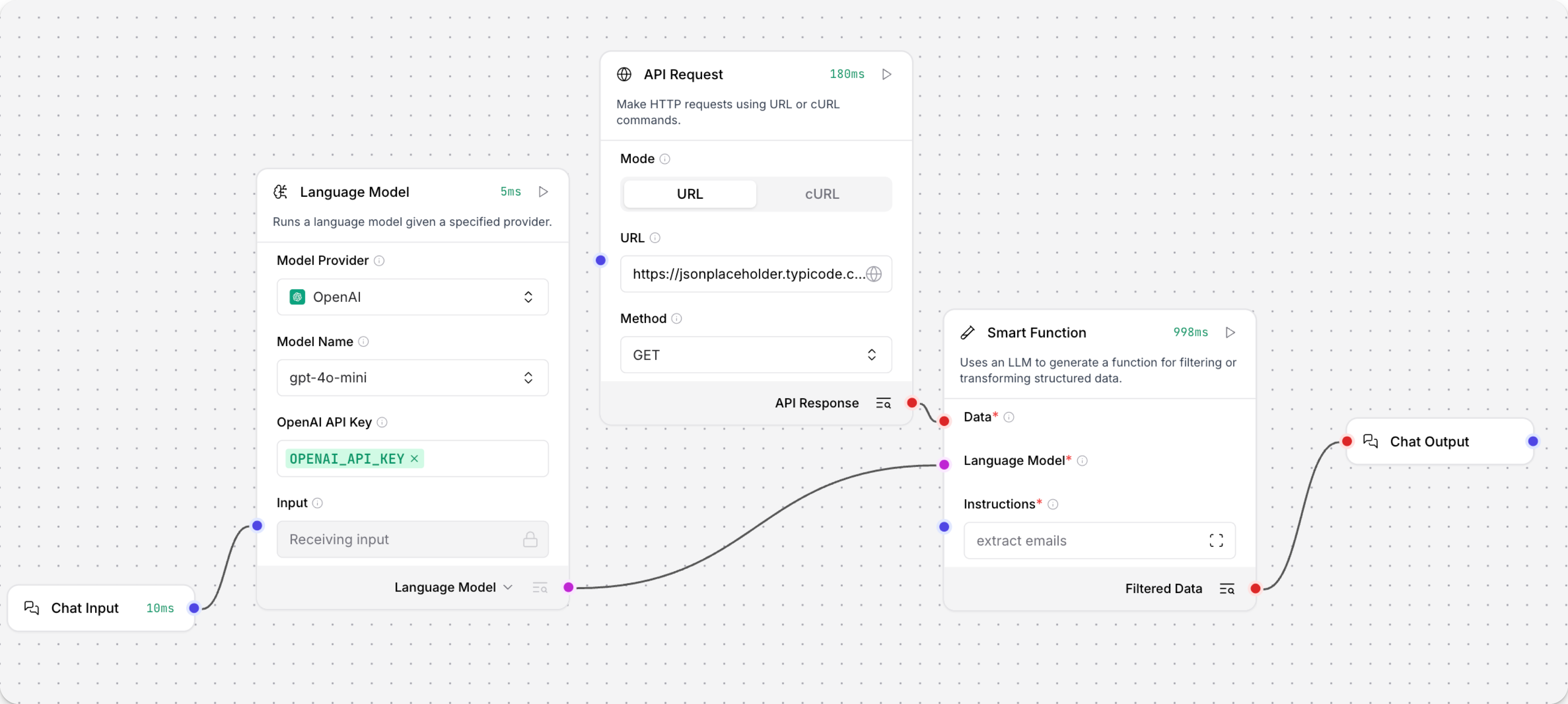
要使用Smart function组件,你必须将其连接到Language Model组件,该组件使用Instructions字段中的自然语言指令来生成函数。
此示例从https://jsonplaceholder.typicode.com/users API端点获取JSON数据。
Smart function组件中的Instructions字段指定任务extract emails。
连接的LLM基于指令创建过滤器,并成功从JSON数据中提取电子邮件地址列表。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | Data | 使用Lambda函数过滤或转换的结构化数据。 |
| llm | Language Model | Model组件的连接端口。 |
| filter_instruction | Instructions | 如何使用Lambda函数过滤或转换数据的自然语言指令,例如过滤数据以仅包含'status'为'active'的项目。 |
| sample_size | Sample Size | 对于大型数据集,从数据集头部和尾部采样的字符数。 |
| max_size | Max Size | 数据被认为是"大型"的字符数,这会触发sample_size值的采样。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| filtered_data | Filtered Data | 过滤或转换后的Data对象。 |
| dataframe | DataFrame | 作为DataFrame的过滤数据。 |
Split Text
此组件根据指定条件将文本分割成块。它非常适合将数据分块以进行标记化并嵌入到向量数据库中。
Split Text组件输出Chunks或DataFrame。
Chunks输出返回单个文本块的列表。
DataFrame输出返回结构化数据格式,应用了额外的text和metadata列。
- 要在流程中使用此组件,将输出Data或DataFrame的组件连接到Split Text组件的Data端口。 此示例使用URL组件,它正在获取JSON占位符数据。
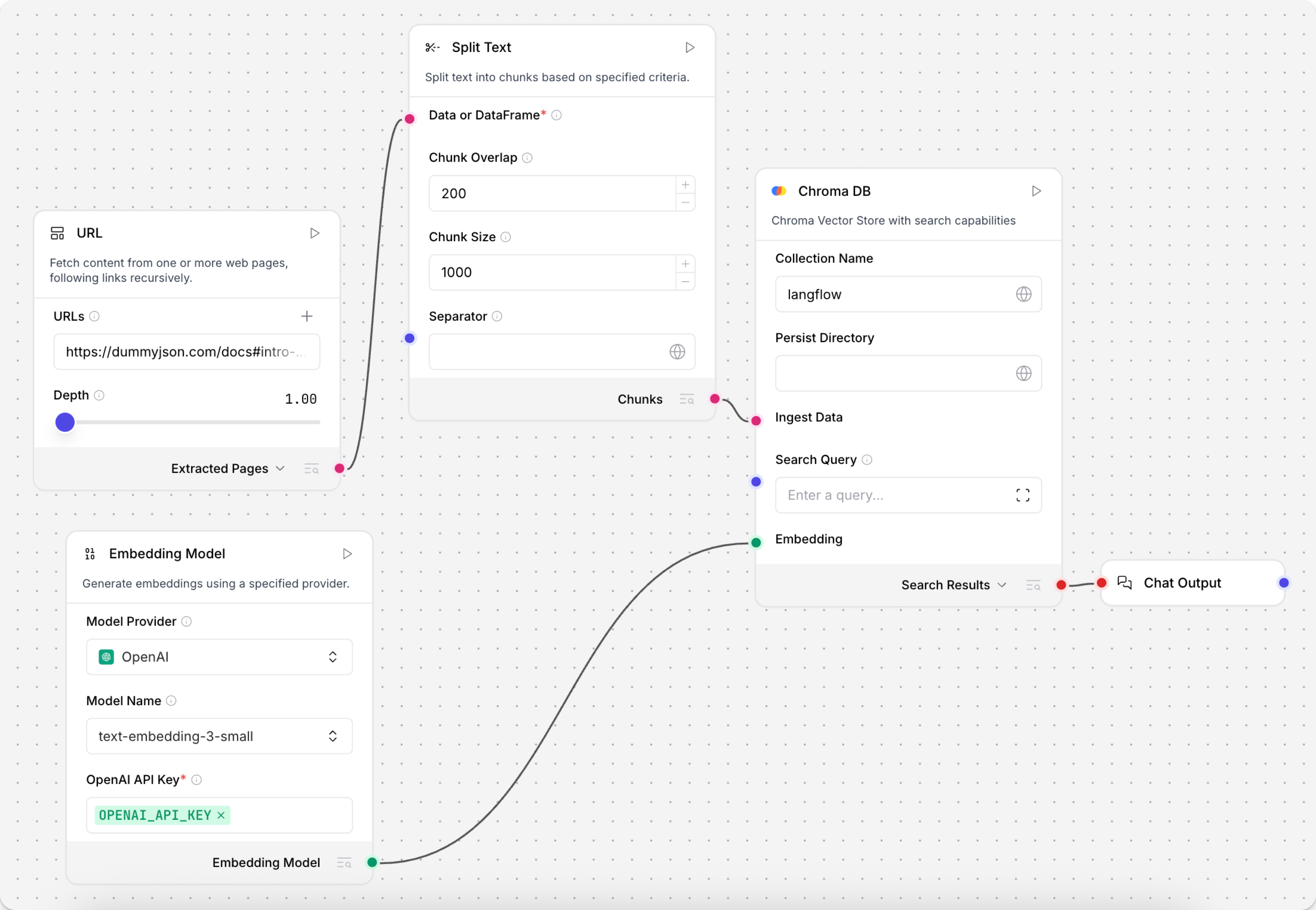
- 在Split Text组件中,定义你的数据分割参数。
此示例在分隔符},处分割传入的JSON数据,因此每个块包含一个JSON对象。
优先级顺序是Separator,然后是Chunk Size,然后是Chunk Overlap。
如果分隔符分割后的任何段落长于chunk_size,它会再次分割以适应chunk_size。
在chunk_size之后,在块之间应用Chunk Overlap以保持上下文。
- 将Chat Output组件连接到Split Text组件的DataFrame输出以查看其输出。
- 点击Playground,然后点击Run Flow。
输出包含在
},处分割的JSON对象表格。
_16{_16"userId": 1,_16"id": 1,_16"title": "Introduction to Artificial Intelligence",_16"body": "Learn the basics of Artificial Intelligence and its applications in various industries.",_16"link": "https://example.com/article1",_16"comment_count": 8_16},_16{_16"userId": 2,_16"id": 2,_16"title": "Web Development with React",_16"body": "Build modern web applications using React.js and explore its powerful features.",_16"link": "https://example.com/article2",_16"comment_count": 12_16},
- 清除Separator字段,然后再次运行流程。 输出包含50个字符的文本行,有10个字符的重叠,而不是JSON对象。
_10First chunk: "title": "Introduction to Artificial Intelligence""_10Second chunk: "elligence", "body": "Learn the basics of Artif"_10Third chunk: "s of Artificial Intelligence and its applications"
参数
其他文本分割器
Structured output
此组件将LLM响应转换为结构化数据格式。
在来自Financial Support Parser模板的此示例中,Structured Output组件将非结构化财务报告转换为结构化数据。
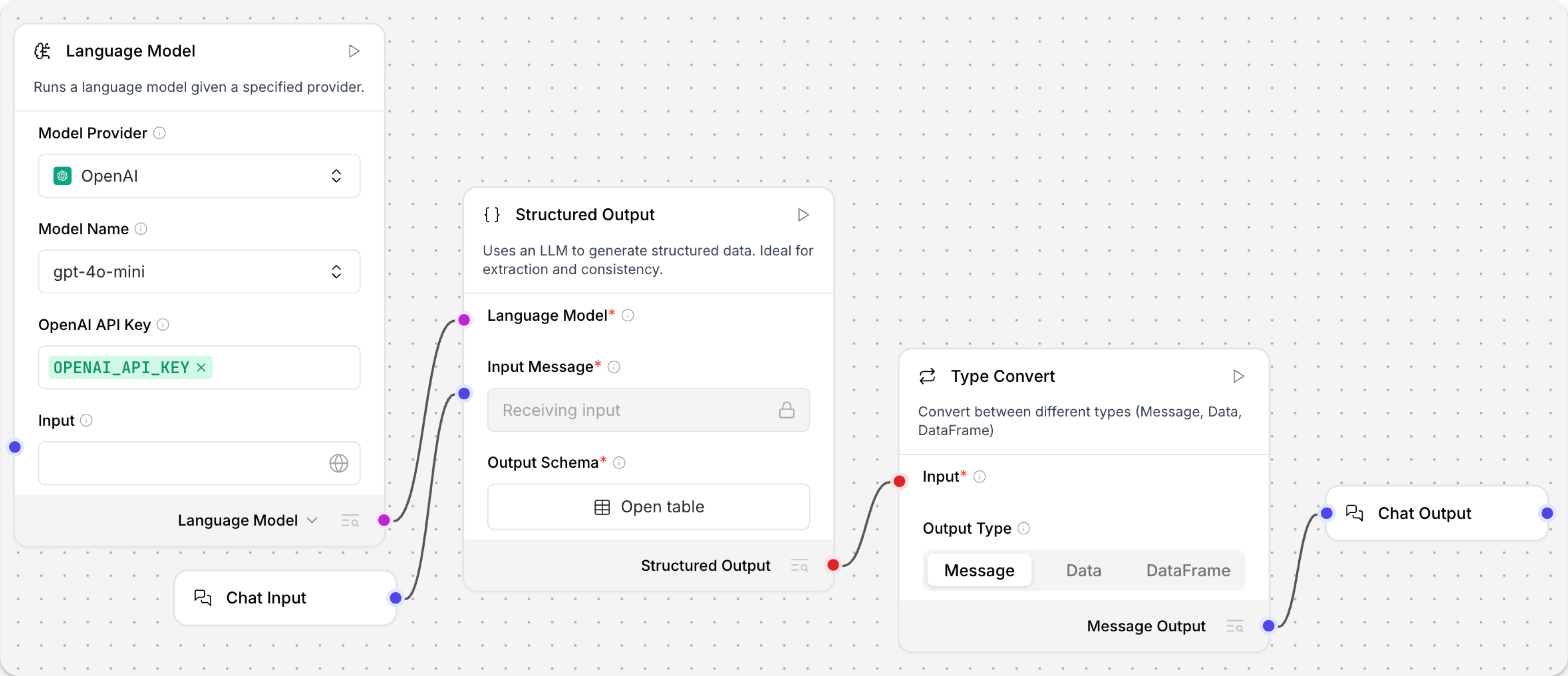
连接的LLM模型通过Structured Output组件的Format Instructions参数提示从非结构化文本中提取结构化输出。Format Instructions用作Structured Output组件的系统提示。
在Structured Output组件中,点击Open table按钮查看Output Schema表格。
Output Schema参数使用包含以下字段的表格定义模型输出的结构和数据类型:
- Name:输出字段的名称。
- Description:输出字段的目的。
- Type:输出字段的数据类型。可用类型为
str、int、float、bool、list或dict。默认为text。 - Multiple:此功能已被弃用。目前,如果你期望单个字段有多个值,它默认设置为
True。例如,features的list设置为True以包含多个值,例如["waterproof", "durable", "lightweight"]。默认:True。
Parse DataFrame组件将结构化输出解析为模板,以便在聊天输出中有序呈现。模板从output_schema表格中接收带有大括号的值。
例如,模板EBITDA: {EBITDA} , Net Income: {NET_INCOME} , GROSS_PROFIT: {GROSS_PROFIT}在Playground中将提取的值呈现为EBITDA: 900 million , Net Income: 500 million , GROSS_PROFIT: 1.2 billion。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| llm | LanguageModel | 用于生成结构化输出的语言模型。 |
| input_value | String | 输入到语言模型的消息。 |
| system_prompt | String | 对语言模型格式化输出的指令。 |
| schema_name | String | 输出数据模式的名称。 |
| output_schema | Table | 模型输出的结构和数据类型。 |
| multiple | Boolean | [已弃用]始终设置为True。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| structured_output | Data | 结构化输出是基于定义模式的Data对象。 |
Type convert
此组件在不同格式之间转换数据类型。它可以在Data、DataFrame和Message对象之间转换数据。
- Data:包含文本和元数据的结构化对象。
_10{_10 "text": "User Profile",_10 "data": {_10 "name": "John Smith",_10 "age": 30,_10 "email": "john@example.com"_10 }_10}
- DataFrame:具有行和列的表格数据结构。 键是列,列表中的每个字典(键值对的集合)是一行。
_12[_12 {_12 "name": "John Smith",_12 "age": 30,_12 "email": "john@example.com"_12 },_12 {_12 "name": "Jane Doe",_12 "age": 25,_12 "email": "jane@example.com"_12 }_12]
- Message:字符串,例如
"Name: John Smith, Age: 30, Email: john@example.com"。
要在流程中使用此组件,请执行以下操作:
- 将Web search组件添加到Basic prompting流程中。在Search Query字段中,输入查询,例如
environmental news。 - 将Web search组件的输出连接到接受DataFrame输入的组件。 此示例使用Prompt组件为聊天机器人提供上下文,因此你必须将Web search组件的DataFrame输出转换为Message类型。
- 连接Type Convert组件以将DataFrame转换为Message。
- 在Type Convert组件的Output Type字段中,选择Message。 你的流程如下所示:
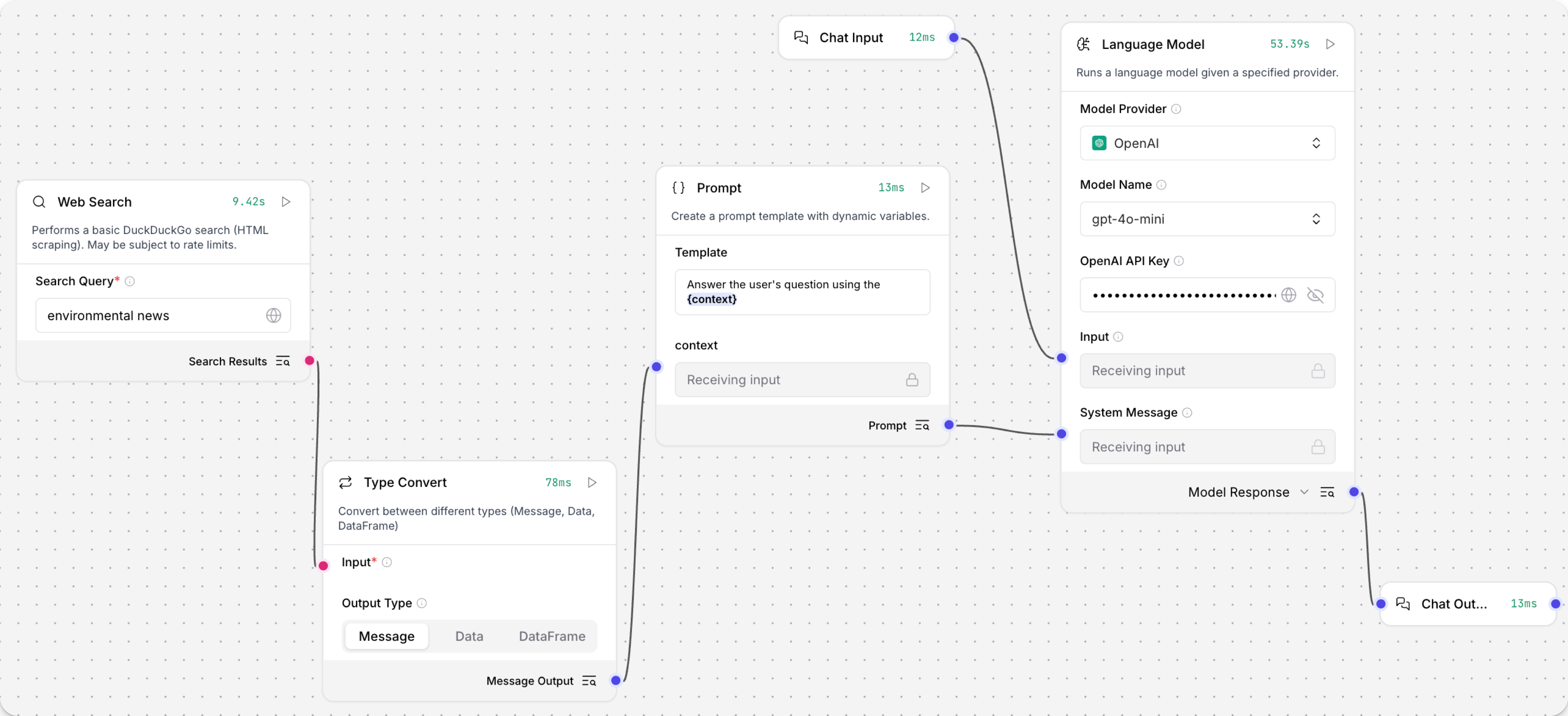
- 在Language Model组件的OpenAI API Key字段中,添加你的OpenAI API密钥。
- 点击Playground,然后询问
latest news。
搜索结果作为消息返回到Playground。
结果:
_10Latest news_10AI_10gpt-4o-mini_10Here are some of the latest news articles related to the environment:_10Ozone Pollution and Global Warming: A recent study highlights that ozone pollution is a significant global environmental concern, threatening human health and crop production while exacerbating global warming. Read more_10...
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_data | Input Data | 要转换的数据。接受Data、DataFrame或Message对象。 |
| output_type | Output Type | 所需的输出类型。选项:Data、DataFrame或Message。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | Output | 指定格式的转换数据。 |
遗留处理组件
以下处理组件是遗留组件。 你仍然可以在流程中使用它们,但它们不再受支持,可能在未来版本中被移除。
尽快用建议的替代方案替换这些组件。
Alter Metadata
用Data Operations组件替换此遗留组件。
此组件修改输入对象的元数据。它可以添加新元数据、更新现有元数据并删除指定的元数据字段。该组件适用于Message和Data对象,还可以从用户提供的文本创建新的Data对象。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_value | Input | 输入参数。应添加元数据的对象。 |
| text_in | User Text | 输入参数。文本输入;值包含在Data对象的'text'属性中。空文本条目被忽略。 |
| metadata | Metadata | 输入参数。要添加到每个对象的元数据。 |
| remove_fields | Fields to Remove | 输入参数。要删除的元数据字段。 |
| data | Data | 输出参数。输入对象的列表,每个都添加了元数据。 |
Combine Data/Merge Data
用Data Operations组件或Loop组件替换此遗留组件。
此组件将多个数据源合并为单个统一的Data对象。
组件遍历Data对象列表,将它们合并为单个Data对象(merged_data)。
如果输入列表为空,它返回一个空数据对象。
如果只有一个输入数据对象,它返回该对象不变。
合并过程使用加法运算符来组合数据对象。
Combine Text
用Data Operations组件替换此遗留组件。
此组件使用指定的分隔符将两个文本输入连接为单个文本块,输出包含组合文本的Message对象。
Create Data
用Data Operations组件替换此遗留组件。
此组件动态创建具有指定字段数和文本键的Data对象。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| number_of_fields | Number of Fields | 输入参数。要添加到记录的字段数。 |
| text_key | Text Key | 输入参数。标识要用作文本内容的字段的键。 |
| text_key_validator | Text Key Validator | 输入参数。如果启用,检查给定的Text Key是否存在于给定的Data中。 |
Extract Key
用Data Operations组件替换此遗留组件。
此组件从Data对象中提取特定键并返回与该键关联的值。
Data to DataFrame/Data to Message
用较新的处理组件替换这些遗留组件,例如Data Operations组件和Type Convert组件。
这些组件将一个或多个Data对象转换为DataFrame或Message对象。
对于Data to DataFrame组件,每个Data对象对应于结果DataFrame中的一行。
.data属性中的字段成为列,.text字段(如果存在)放置在text列中。
Filter Data
用Data Operations组件替换此遗留组件。
此组件基于键列表(filter_criteria)过滤Data对象,返回只包含与过滤条件匹配的键值对的新Data对象(filtered_data)。
Filter Values
用Data Operations组件替换此遗留组件。
Filter values组件基于指定的键、过滤值和比较运算符过滤数据项列表。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_data | Input data | 输入参数。要过滤的数据项列表。 |
| filter_key | Filter Key | 输入参数。要过滤的键。 |
| filter_value | Filter Value | 输入参数。要过滤的值。 |
| operator | Comparison Operator | 输入参数。用于比较值的运算符。 |
| filtered_data | Filtered data | 输出参数。过滤后的数据项的结果列表。 |
JSON Cleaner
用Parser组件替换此遗留组件。
此组件清理JSON字符串以确保它们完全符合JSON规范。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| json_str | JSON String | 输入参数。要清理的JSON字符串。这可以是由语言模型或其他可能不完全符合JSON规范的源产生的原始、可能格式错误的JSON字符串。 |
| remove_control_chars | Remove Control Characters | 输入参数。如果设置为True,此选项从JSON字符串中删除控制字符(ASCII字符0-31和127)。这可以帮助消除可能导致解析问题或使JSON无效的不可见字符。 |
| normalize_unicode | Normalize Unicode | 输入参数。启用时,此选项将JSON字符串中的Unicode字符标准化为其规范��组合形式(NFC)。这确保了Unicode字符在不同系统间的一致表示,并防止字符编码的潜在问题。 |
| validate_json | Validate JSON | 输入参数。如果设置为True,此选项尝试解析JSON字符串以确保在应用最终修复操作之前它是格式良好的。如果JSON无效,它会引发ValueError,允许早期检测JSON中的主要结构问题。 |
| output | Cleaned JSON String | 输出参数。完全符合JSON规范的结果清理、修复和验证JSON字符串。 |
Message to Data
用Type Convert组件替换此遗留组件。
此组件将Message对象转换为Data对象。
Parse DataFrame
用DataFrame Operations组件或Parser组件替换此遗留组件。
此组件使用模板将DataFrame对象转换为纯文本。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| df | DataFrame | 输入参数。要转换为文本行的DataFrame。 |
| template | Template | 输入参数。格式化模板(使用{column_name}占位符)。 |
| sep | Separator | 输入参数。在输出中连接行的字符串。 |
| text | Text | 输出参数。合并为单个文本的所有行。 |
Parse JSON
用Parser组件替换此遗留组件。
此组件使用JQ查询转换和提取Message和Data对象中的JSON字段,然后返回filtered_data,它是Data对象的列表。
Python REPL
用Python Interpreter组件或其他处理或逻辑组件替换此遗留组件。
此组件创建用于执行Python代码的Python REPL(读取-评估-打印循环)工具。
它接受以下参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| name | String | 输入参数。工具的名称。默认:python_repl。 |
| description | String | 输入参数。工具功能的描述。 |
| global_imports | List[String] | 输入参数。要全局导入的模块列表。默认:math。 |
| tool | Tool | 输出参数。用于LangChain的Python REPL工具。 |
Python Code Structured
用Python Interpreter组件或其他处理或逻辑组件替换此遗留组件。
此组件使用数据类从Python代码创建结构化工具。
组件根据提供的Python代码动态更新其配置,允许自定义函数参数和描述。
它接受以下参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| tool_code | String | 输入参数。工具数据类的Python代码。 |
| tool_name | String | 输入参数。工具的名称。 |
| tool_description | String | 输入参数。工具的描述。 |
| return_direct | Boolean | 输入参数。是否直接返回函数输出。 |
| tool_function | String | 输入参数。工具的选定函数。 |
| global_variables | Dict | 输入参数。工具的全局变量或数据。 |
| result_tool | Tool | 输出参数。从Python代码创建的结构化工具。 |
Regex Extractor
用Parser组件替换此遗留组件。
此组件使用正则表达式提取文本中的模式。它可以用于查找和提取文本中的特定模式或信息。
Select Data
用Data Operations组件替换此遗留组件。
此组件从列表中选择单个Data对象。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data_list | Data List | 输入参数。要选择的数据列表 |
| data_index | Data Index | 输入参数。要选择的数据索引 |
| selected_data | Selected Data | 输出参数。选定的Data对象。 |
Update Data
用Data Operations组件替换此遗��留组件。
此组件动态更新或追加具有指定字段的数据。
它接受以下参数:
| 名称 | 显示名称 | 信息 |
|---|---|---|
| old_data | Data | 输入参数。要更新的记录。 |
| number_of_fields | Number of Fields | 输入参数。要添加的字段数。最大为15。 |
| text_key | Text Key | 输入参数。文本内容的键。 |
| text_key_validator | Text Key Validator | 输入参数。验证文本键存在。 |
| data | Data | 输出参数。更新的Data对象。 |