Data
您可以使用 Langflow 的数据组件从各种来源(如文件、API 端点和 URL)将数据带入您的 flow 中。 例如:
-
搜索网络:使用 News Search、RSS Reader、Web Search 和 URL 等组件从网络获取数据。
-
进行 API 调用:使用 API Request 和 Webhook 组件使用 API 触发 flow 或执行操作。
-
运行 SQL 查询:使用 SQL Database 组件查询 SQL 数据库。
每个组件都运行不同的命令来进行检索、处理和类型检查。 一些组件是您提供的命令的最小包装器,而其他组件包含内置脚本来根据变量输入获取和处理数据。 此外,一些组件返回原始数据,而其他组件可以在输出之前转换、重构或验证数据。 这意味着一些类似的组件可能会产生不同的结果。
数据组件与处理组件配合得很好,后者可以在检索数据后执行额外的解析、转换和验证。
这可以包括基本操作,如以特定格式保存文件,或更复杂的任务,如使用 Text Splitter 组件将大文档分解为更小的块,然后为向量搜索生成嵌入。
在 flow 中使用数据组件
数据组件在 flow 中经常使用,因为它们提供了执行常见基本功能的多种方式。
您可以使用数据组件在 flow 中执行其基本功能作为独立步骤,或者您可以将它们作为工具连接到 Agent 组件。
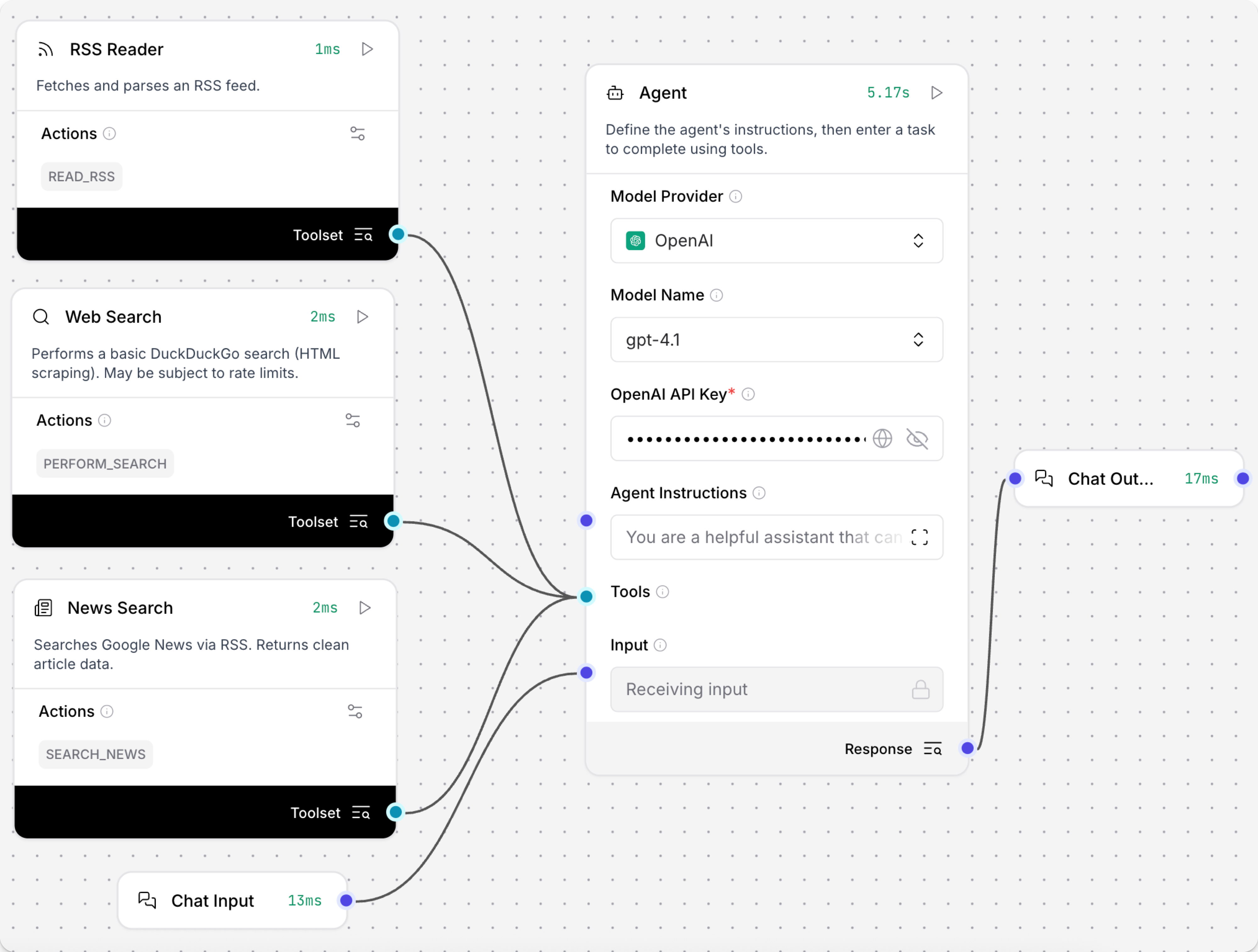
有关 flow 中数据组件的示例,请参阅以下内容:
-
创建可以接收文件的聊天机器人:学习如何使用 File 组件将文件作为聊天机器人的上下文加载。 文件和用户输入都传递给 LLM,因此您可以对上传的文件提问。
-
创建向量 RAG 聊天机器人:学习如何接收文件用于检索增强生成 (RAG),然后设置一个可以使用接收的文件作为上下文的聊天机器人。 本教程中的两个 flow 为 RAG 准备文件,然后让您的 LLM 在聊天会话期间使用向量搜索来检索上下文相关数据��。
-
为 Agent 配置工具:学习如何将任何组件用作 Agent 的工具。 当用作工具时,Agent 会根据用户的查询自主决定何时调用组件。
-
使用 webhook 触发 flow:学习如何使用 Webhook 组件响应外部事件触发 flow 运行。
API Request
API Request 组件使用 URL 或 curl 命令构建和发送 HTTP 请求:
- URL 模式:输入一个或多个以逗号分隔的 URL,然后为每个 URL 的请求选择方法。
- curl 模式:输入要执行的 curl 命令。
您可以在组件参数中启用额外的请求选项和字段。
返回包含响应的 Data 对象。
有关特定提供商的 API 组件,请参阅 Bundles。
API Request 参数
API Request 组件的大多数输入参数在可视化编辑器中默认隐藏。 您可以通过组件标题菜单中的 Controls 切换参数。
| 名称 | 显示名称 | 信息 |
|---|---|---|
| mode | Mode | 输入参数。将模式设置为 URL 或 curl。 |
| urls | URL | 输入参数。为请求输入一个或多个以逗号分隔的 URL。 |
| curl | cURL | 输入参数。仅限 curl 模式。输入完整的 curl 命令。其他组件参数从命令参数中填充。 |
| method | Method | 输入参数。要使用的 HTTP 方法。 |
| query_params | Query Parameters | 输入参数。要附加到 URL 的查询参数。 |
| body | Body | 输入参数。作为字典与 POST、PATCH 和 PUT 请求一起发送的主体。 |
| headers | Headers | 输入参数。作为字典与请求一起发送的头信息。 |
| timeout | Timeout | 输入参数。请求使用的超时时间。 |
| follow_redirects | Follow Redirects | 输入参数。是否跟随 http 重定向。默认值:启用/true |
| save_to_file | Save to File | 输入参数。是否将 API 响应保存到临时文件。默认值:禁用/false |
| include_httpx_metadata | Include HTTPx Metadata | 输入参数。是否在输出中包含诸如 headers、status_code、response_headers 和 redirection_history 等属性。默认值:禁用/false |
Directory
Directory 组件递归地从目录加载文件,提供文件类型、深度和并发选项。
文件必须是支持的类型和大小才能被加载。
Directory 参数
Directory 组件的许多输入参数在可视化编辑器中默认隐藏。 您可以通过组件标题菜单中的 Controls 切换参数。
| 名称 | 类型 | 描述 |
|---|---|---|
| path | MessageTextInput | 输入参数。要从中加载文件的目录路径。默认值:当前目录 (.) |
| types | MessageTextInput | 输入参数。要加载的文件类型。选择一个或多个,或留空以尝试加载所有文件。 |
| depth | IntInput | 输入参数。搜索文件的深度。 |
| max_concurrency | IntInput | 输入参数。加载多个文件的最大并发数。 |
| load_hidden | BoolInput | 输入参数。如果为 true,则加载隐藏文件。 |
| recursive | BoolInput | 输入参数。如果为 true,则搜索是递归的。 |
| silent_errors | BoolInput | 输入参数。如果为 true,错误不会引发异常。 |
| use_multithreading | BoolInput | 输入参数。如果为 true,则使用多线程。 |
File
The File component loads and parses files, converts the content into a Data, DataFrame, or Message object.
It supports multiple file types and provides parameters for parallel processing and error handling.
You can add files to the File component in the visual editor or at runtime, and you can upload multiple files at once. For more information about uploading files and working with files in flows, see File management and Create a chatbot that can ingest files.
File type and size limits
By default, the maximum file size is 100 MB.
To modify this value, change the --max-file-size-upload environment variable.
Supported file types
The following file types are supported by the File component. Use archive and compressed formats to bundle multiple files together, or use the Directory component to load all files in a directory.
.bz2.csv.docx.gz.htm.html.json.js.md.mdx.pdf.py.sh.sql.tar.tgz.ts.tsx.txt.xml.yaml.yml.zip
If you need to load an unsupported file type, you must use a different component that supports that file type and, potentially, parses it outside Langflow, or you must convert it to a supported type before uploading it.
For images, see Upload images.
For videos, see the Twelve Labs and YouTube bundles in the Langflow Components menu.
File parameters
Most File component input parameters are hidden by default in the visual editor. You can toggle parameters through the Controls in the component's header menu.
| Name | Display Name | Info |
|---|---|---|
| path | Files | Input parameter. The path to files to load. Can be local or in Langflow file management. Supports individual files and bundled archives. |
| file_path | Server File Path | Input parameter. A Data object with a file_path property pointing to a file in Langflow file management or a Message object with a path to the file. Supersedes Files (path) but supports the same file types. |
| separator | Separator | Input parameter. The separator to use between multiple outputs in Message format. |
| silent_errors | Silent Errors | Input parameter. If true, errors in the component don't raise an exception. The default is false/disabled. |
| delete_server_file_after_processing | Delete Server File After Processing | Input parameter. If true (default), the Server File Path (file_path) is deleted after processing. |
| ignore_unsupported_extensions | Ignore Unsupported Extensions | Input parameter. If true/enabled (default), files with unsupported extensions are accepted but not processed. If false/disabled, the File component either can throw an error if an unsupported file type is provided. |
| ignore_unspecified_files | Ignore Unspecified Files | Input parameter. If true, Data with no file_path property is ignored. If false (default), the component errors when a file is not specified. |
| concurrency_multithreading | Processing Concurrency | Input parameter. The number of files to process concurrently if multiple files are uploaded. Default is 1. Values greater than 1 enable parallel processing for 2 or more files. |
File output
The output of the File component depends on the number and type of files loaded:
-
No files: Throws an error or, if Silent Errors is enabled, produces no output.
-
One file: Produces one of the following depending on the file type. If multiple types are available, you can select the output type by clicking the output field (near the component's output port).
- Structured Content: Available for some tabular and structured data.
For
.csvfiles, produces aDataFramerepresenting the table data. For.jsonfiles, produces aDataobject with the parsed JSON data. - Raw Content: A
Messagecontaining the file's raw text content. - File Path: A
Messagecontaining the path to the file in Langflow file management.
- Structured Content: Available for some tabular and structured data.
For
-
Multiple files: Produces a Files
DataFramecontaining the content and metadata of all selected files.
News Search
The News Search component searches Google News through RSS, and then returns clean article data as a DataFrame containing article titles, links, publication dates, and summaries.
The component's clean_html method parses the HTML content with the BeautifulSoup library, removes HTML markup, and strips whitespace to output clean data.
For other RSS feeds, use the RSS Reader component, and for other searches use the Web Search component or a provider-specific bundle.
When used as a standard component in a flow, the News Search component must be connected to a component that accepts DataFrame input.
You can connect the News Search component directly to a compatible component, or you can use a processing component to convert or extract data of a different type between components.
When used in Tool Mode with an Agent component, the News Search component can be connected directly to the Agent component's Tools port without converting the data.
The agent decides whether to use the News Search component based on the user's query, and it can process the DataFrame output directly.
News Search parameters
Most News Search component input parameters are hidden by default in the visual editor. You can toggle parameters through the Controls in the component's header menu.
| Name | Display Name | Info |
|---|---|---|
| query | Search Query | Input parameter. Search keywords for news articles. |
| hl | Language (hl) | Input parameter. Language code, such as en-US, fr, de. Default: en-US. |
| gl | Country (gl) | Input parameter. Country code, such as US, FR, DE. Default: US. |
| ceid | Country:Language (ceid) | Input parameter. Language, such as US:en, FR:fr. Default: US:en. |
| topic | Topic | Input parameter. One of: WORLD, NATION, BUSINESS, TECHNOLOGY, ENTERTAINMENT, SCIENCE, SPORTS, HEALTH. |
| location | Location (Geo) | Input parameter. City, state, or country for location-based news. Leave blank for keyword search. |
| timeout | Timeout | Input parameter. Timeout for the request in seconds. |
| articles | News Articles | Output parameter. A DataFrame with the key columns title, link, published and summary. |
RSS Reader
The RSS Reader component fetches and parses RSS feeds from any valid RSS feed URL, and then returns the feed content as a DataFrame containing article titles, links, publication dates, and summaries.
When used as a standard component in a flow, the RSS Reader component must be connected to a component that accepts DataFrame input.
You can connect the RSS Reader component directly to a compatible component, or you can use a processing component to convert or extract data of a different type between components.
When used in Tool Mode with an Agent component, the RSS Reader component can be connected directly to the Agent component's Tools port without converting the data.
The agent decides whether to use the RSS Reader component based on the user's query, and it can process the DataFrame output directly.
RSS Reader parameters
| Name | Display Name | Info |
|---|---|---|
| rss_url | RSS Feed URL | Input parameter. URL of the RSS feed to parse, such as https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml. |
| timeout | Timeout | Input parameter. Timeout for the RSS feed request in seconds. Default: 5. |
| articles | Articles | Output parameter. A DataFrame containing the key columns title, link, published and summary. |
SQL Database
The SQL Database component executes SQL queries on SQLAlchemy-compatible databases. It supports any SQLAlchemy-compatible database, such as PostgreSQL, MySQL, and SQLite.
For CQL queries, see the DataStax bundle.
Query an SQL database with natural language prompts
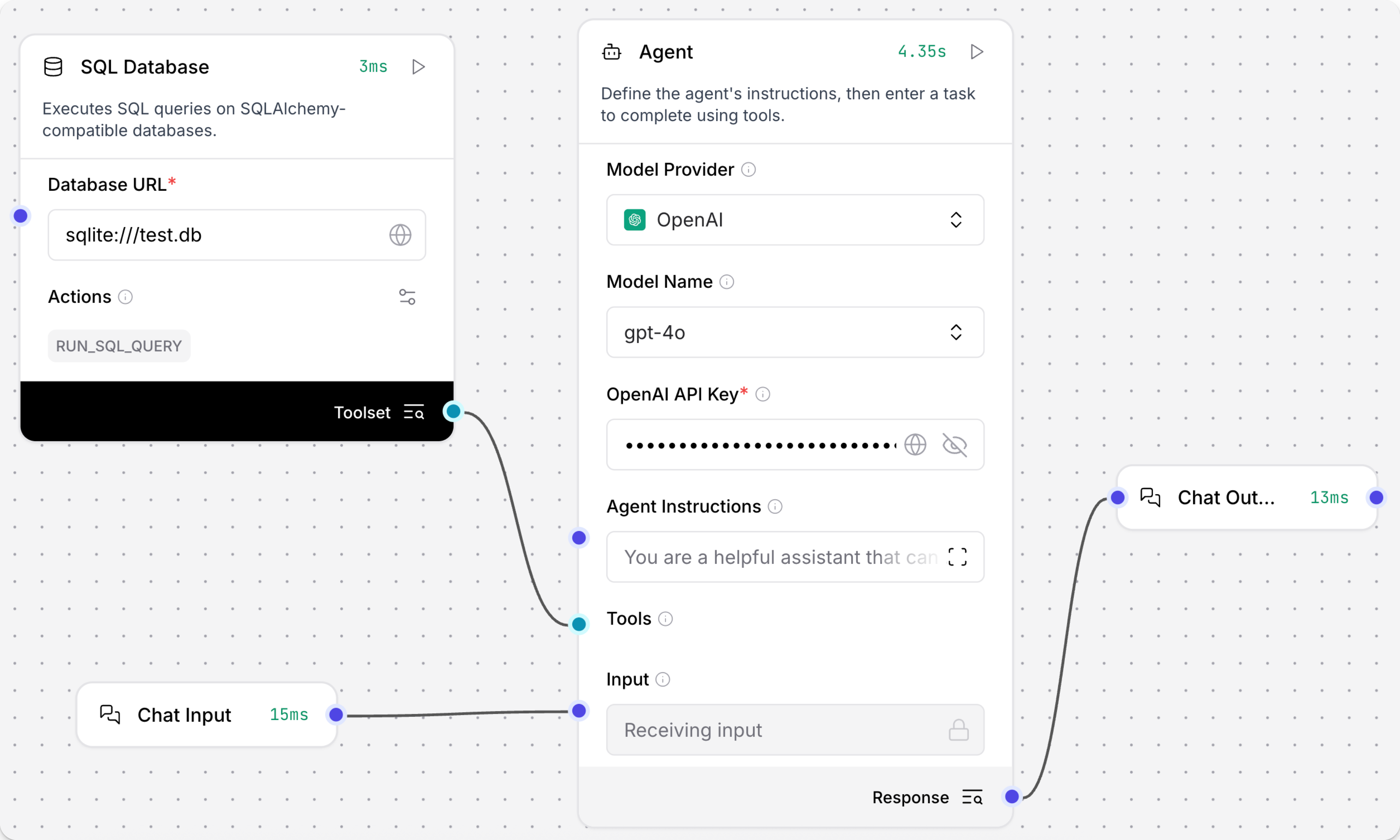
The following example demonstrates how to use the SQL Database component in a flow, and then modify the component to support natural language queries through an Agent component.
This allows you to use the same SQL Database component for any query, rather than limiting it to a single manually entered query or requiring the user, application, or another component to provide valid SQL syntax as input. Users don't need to master SQL syntax because the Agent component translates the users' natural language prompts into SQL queries, passes the query to the SQL Database component, and then returns the results to the user.
Additionally, input from applications and other components doesn't have to be extracted and transformed to exact SQL queries. Instead, you only need to provide enough context for the agent to understand that it should create and run a SQL query according to the incoming data.
-
Use your own sample database or create a test database.
Create a test SQL database
-
Create a database called
test.db:_10sqlite3 test.db -
Add some values to the database:
_13sqlite3 test.db "_13CREATE TABLE users (_13id INTEGER PRIMARY KEY,_13name TEXT,_13email TEXT,_13age INTEGER_13);_13_13INSERT INTO users (name, email, age) VALUES_13('John Doe', 'john@example.com', 30),_13('Jane Smith', 'jane@example.com', 25),_13('Bob Johnson', 'bob@example.com', 35);_13" -
Verify that the database has been created and contains your data:
_10sqlite3 test.db "SELECT * FROM users;"The result should list the text data you entered in the previous step:
_101|John Doe|john@example.com_102|Jane Smith|jane@example.com_103|John Doe|john@example.com_104|Jane Smith|jane@example.com
-
-
Add an SQL Database component to your flow.
-
In the Database URL field, add the connection string for your database, such as
sqlite:///test.db.At this point, you can enter an SQL query in the SQL Query field or use the port to pass a query from another component, such as a Chat Input component. If you need more space, click Expand to open a full-screen text field.
However, to make this component more dynamic in an agentic context, use an Agent component to transform natural language input to SQL queries, as explained in the following steps.
-
Click the SQL Database component to expose the component's header menu, and then enable Tool Mode.
You can now use this component as a tool for an agent. In Tool Mode, no query is set in the SQL Database component because the agent will generate and send one if it determines that the tool is required to complete the user's request. For more information, see Configure tools for agents.
-
Add an Agent component to your flow, and then enter your OpenAI API key.
The default model is an OpenAI model. If you want to use a different model, edit the Model Provider, Model Name, and API Key fields accordingly.
If you need to execute highly specialized queries, consider selecting a model that is trained for tasks like advanced SQL queries. If your preferred model isn't in the Agent component's built-in model list, select the Custom model provider, and then use a Language Model component to attach a specific model.
-
Connect the SQL Database component's Toolset output to the Agent component's Tools input.
-
Click Playground, and then ask the agent a question about the data in your database, such as
Which users are in my database?The agent determines that it needs to query the database to answer the question, uses the LLM to generate an SQL query, and then uses the SQL Database component's
RUN_SQL_QUERYaction to run the query on your database. Finally, it returns the results in a conversational format, unless you provide instructions to return raw results or a different format.The following example queried a test database with little data, but with a more robust dataset you could ask more detailed or complex questions.
_10Here are the users in your database:_10_101. **John Doe** - Email: john@example.com_102. **Jane Smith** - Email: jane@example.com_103. **John Doe** - Email: john@example.com_104. **Jane Smith** - Email: jane@example.com_10_10It seems there are duplicate entries for the users.
SQL Database parameters
Some SQL Database component input parameters are hidden by default in the visual editor. You can toggle parameters through the Controls in the component's header menu.
| Name | Display Name | Info |
|---|---|---|
| database_url | Database URL | Input parameter. The SQLAlchemy-compatible database connection URL. |
| query | SQL Query | Input parameter. The SQL query to execute, which can be entered directly, passed in from another component, or, in Tool Mode, automatically provided by an Agent component. |
| include_columns | Include Columns | Input parameter. If enabled, includes column names in the result. The default is enabled (true). |
| add_error | Add Error | Input parameter. If enabled, adds any error messages to the result, if any are returned. The default is disabled (false). |
| run_sql_query | Result Table | Output parameter. The query results as a DataFrame. |
URL
The URL component fetches content from one or more URLs, processes the content, and returns it in various formats. It follows links recursively to a given depth, and it supports output in plain text or raw HTML.
URL parameters
Most URL component input parameters are hidden by default in the visual editor. You can toggle parameters through the Controls in the component's header menu.
Some of the available parameters include the following:
| Name | Display Name | Info |
|---|---|---|
| urls | URLs | Input parameter. One or more URLs to crawl recursively. In the visual editor, click Add URL to add multiple URLs. |
| max_depth | Depth | Input parameter. Controls link traversal: how many "clicks" away from the initial page the crawler will go. A depth of 1 limits the crawl to the first page at the given URL only. A depth of 2 means the crawler crawls the first page plus each page directly linked from the first page, then stops. This setting exclusively controls link traversal; it doesn't limit the number of URL path segments or the domain. |
| prevent_outside | Prevent Outside | Input parameter. If enabled, only crawls URLs within the same domain as the root URL. This prevents the crawler from accessing sites outside the given URL's domain, even if they are linked from one of the crawled pages. |
| use_async | Use Async | Input parameter. If enabled, uses asynchronous loading which can be significantly faster but might use more system resources. |
| format | Output Format | Input parameter. Sets the desired output format as Text or HTML. The default is Text. For more information, see URL output. |
| timeout | Timeout | Input parameter. Timeout for the request in seconds. |
| headers | Headers | Input parameter. The headers to send with the request if needed for authentication or otherwise. |
Additional input parameters are available for error handling and encoding.
URL output
There are two settings that control the output of the URL component at different stages:
-
Output Format: This optional parameter controls the content extracted from the crawled pages:
- Text (default): The component extracts only the text from the HTML of the crawled pages.
- HTML: The component extracts the entire raw HTML content of the crawled pages.
-
Output data type: In the component's output field (near the output port) you can select the structure of the outgoing data when it is passed to other components:
When used as a standard component in a flow, the URL component must be connected to a component that accepts the selected output data type (DataFrame or Message).
You can connect the URL component directly to a compatible component, or you can use a Type Convert component to convert the output to another type before passing the data to other components if the data types aren't directly compatible.
Processing components, like the Type Convert component, are useful with the URL component because it can extract a large amount of data from the crawled pages. 例如,如果您只想将特定字段传递给其他组件,您可以使用 Parser 组件 在将数据传递给其他组件之前仅从爬取的页面中提取那些数据。
当与 Agent 组件在 Tool Mode 中使用时,URL 组件可以直接连接到 Agent 组件的 Tools 端口而无需转换数据。
Agent 根据用户的查询决定是否使用 URL 组件,并且可以直接处理 DataFrame 或 Message 输出。
Web Search
Web Search 组件使用 DuckDuckGo 的 HTML 抓取接口执行基本网络搜索。 对于其他搜索 API,请参阅 Bundles。
Web Search 组件使用网络抓取,可能会受到速率限制。
对于生产使用,请考虑使用具有更强大 API 支持的其他搜索组件,例如特定提供商的包。
在流程中使用 Web Search 组件
以下步骤演示了在流程中使用 Web Search 组件的一种方法:
-
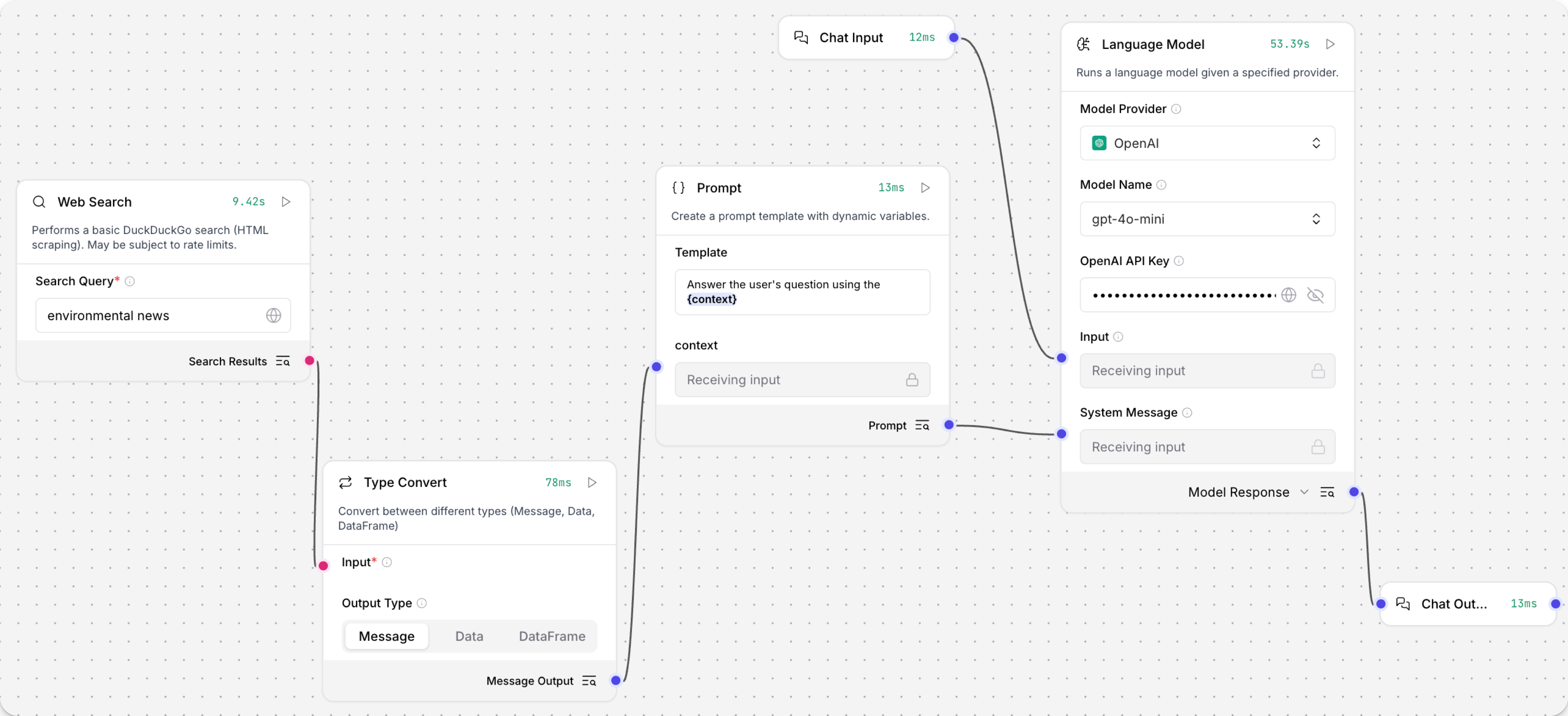
基于 Basic Prompting 模板创建一个流程。
-
添加一个 Web Search 组件,然后输入搜索查询,例如
environmental news。 -
添加一个 Type Convert 组件,将 Output Type 设置为 Message,然后将 Web Search 组件的输出连接到 Type Convert 组件的输入。
默认情况下,Web Search 组件输出
DataFrame。 因为 Prompt Template 组件只接受Message数据,所以需要这种转换,以便流程可以将搜索结果传递给 Prompt Template 组件。 有关更多信息,请参阅 Web Search 输出。 -
在 Prompt Template 组件的 Template 字段中,添加一个变量,如
{searchresults}或{context}。这会向 Prompt Template 组件添加一个字段,您可以使用它将转换后的搜索结果传递给提示。
-
将 Type Convert 组件的输出连接到 Prompt Template 组件上的新变量字段。
-
在 Language Model 组件中,添加您的 OpenAI API 密钥,或选择不同的提供商和模型。
-
单击 Playground,然后输入
latest news。LLM 处理请求,包括通过 Prompt Template 组件传递的上下文,然后在 Playground 聊天界面中打印响应。
结果
以下是可能响应的示例。 您的响应可能会根据网络的当前状态、您的特定查询、模型和其他因素而有所不同。
_10以下是一些与环境相关的最新新闻文章:_10臭氧污染和全球变暖:最近的一项研究强调,臭氧污染是一个重大的全球环境问题,威胁人类健康和农作物生产,同时加剧全球变暖。阅读更多_10...
Web Search 参数
| 名称 | 显示名称 | 信息 |
|---|---|---|
| query | Search Query | 输入参数。要搜索的关键词。 |
| timeout | Timeout | 输入参数。网络搜索请求的超时时间(秒)。默认:5。 |
| results | Search Results | 输出参数。返回包含 title、links 和 snippets 的 DataFrame。有关更多信息,请参阅 Web Search 输出。 |
Web Search 输出
Web Search 组件输出包含关键列 title、links 和 snippets 的 DataFrame。
当在流程中用作标准组件时,Web Search 组件必须连接到接受 DataFrame 输入的组件,或者您必须使用 Type Convert 组件 在将数据传递给其他组件之前将输出转换为 Data 或 Message 类型。
当与 Agent 组件在 Tool Mode 中使用时,Web Search 组件可以直接连接到 Agent 组件的 Tools 端口而无需转换数据。
Agent 根据用户的查询决定是否使用 Web Search 组件,并且可以直接处理 DataFrame 输出。
Webhook
Webhook 组件定义了一个在收到 HTTP POST 请求时运行流程的 webhook 触发器。
触发 webhook
当您向流程添加 Webhook 组件时,会在流程的 API Access 面板中添加一个 Webhook cURL 选项卡。 此选项卡自动生成一个 HTTP POST 请求代码片段,您可以使用它通过 Webhook 组件触发您的流程。 例如:
_10curl -X POST \_10 "http://$LANGFLOW_SERVER_ADDRESS/api/v1/webhook/$FLOW_ID" \_10 -H 'Content-Type: application/json' \_10 -H 'x-api-key: $LANGFLOW_API_KEY' \_10 -d '{"any": "data"}'
有关更多信息,请参阅使用 webhook 触发流程。
Webhook 参数
| 名称 | 显示名称 | 描述 |
|---|---|---|
| data | Payload | 输入参数。通过 HTTP POST 请求从外部系统接收负载。 |
| curl | cURL | 输入参数。向此 webhook 发出请求的 cURL 命令模板。 |
| endpoint | Endpoint | 输入参数。此 webhook 接收请求的端点 URL。 |
| output_data | Data | 输出参数。来自 webhook 输入的处理数据。如果未提供输入,则返回空的 Data 对象。如果输入不是有效的 JSON,Webhook 组件会将其包装在 payload 对象中,以便可以接受为触发流程的输入。 |
额外的数据组件
Langflow 的核心组件旨在通用并�支持各种用例。 核心组件通常不限于单个提供商。
如果核心数据组件不能满足您的需求,您可以在 Components 菜单的 Bundles 部分找到特定提供商的组件。
例如,DataStax 包包含用于 CQL 查询的组件,Google 包包含用于 Google Search API 的组件。
遗留数据组件
Load CSV 和 Load JSON 组件是遗留组件。 您仍然可以在流程中使用它们,但它们不再维护,可能会在未来版本中被移除。
用 File 组件替换这些组件,它支持加载 CSV 和 JSON 文件以及许多其他文件类型。