向量存储
Langflow 的向量存储组件连接到您的向量数据库或创建内存向量存储,用于在流程中存储和检索向量数据。
向量数据库和向量存储组件专门设计用于存储和检索向量数据,例如语言模型生成的嵌入。它们用于执行相似性搜索,使聊天机器人等应用程序能够从大型数据集中检索相关上下文。
其他类型的存储,如传统的结构化数据库和聊天记忆,通过其他组件处理,如 SQL Database 组件或 Message History 组件。
在流程中使用向��量存储组件
有关流程中向量存储组件的示例,请参阅创建向量 RAG 聊天机器人和嵌入模型组件。
此示例使用 Chroma DB 向量存储组件。您的向量存储组件的参数和身份验证可能不同,但文档摄取工作流程是相同的。从本地机器加载文档并分块。向量存储组件使用连接的模型组件生成嵌入,并将它们存储在连接的向量数据库中。
然后可以检索此向量数据用于检索增强生成等工作负载。
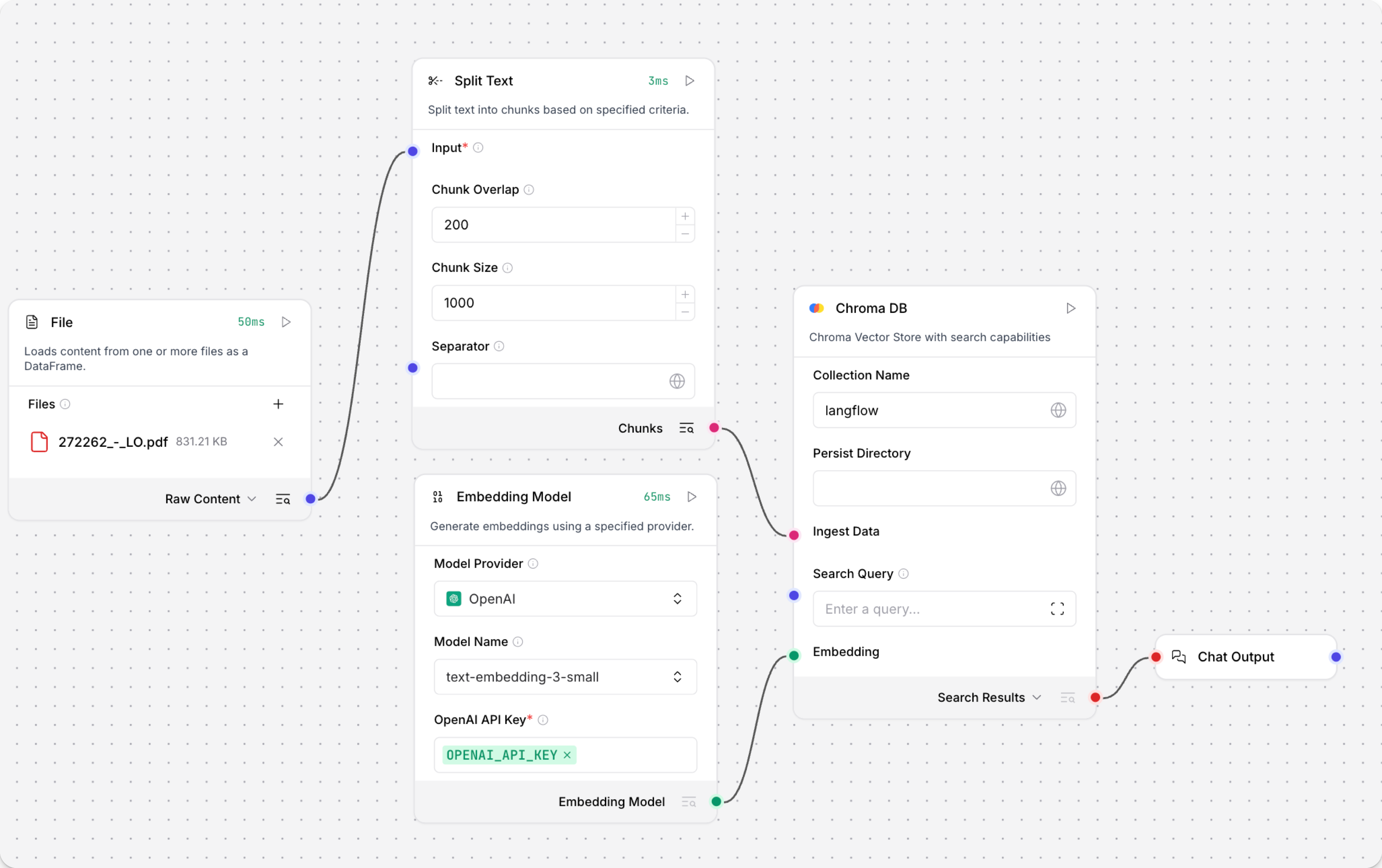
用户的聊天输入被嵌入并与在文档摄取期间嵌入的向量进行比较以进行相似性搜索。
结果从向量数据库组件作为 Data 对象输出并解析为文本�。
此文本填充 Prompt Template 组件中的 {context} 变量,为 OpenAI model 组件的响应提供信息。
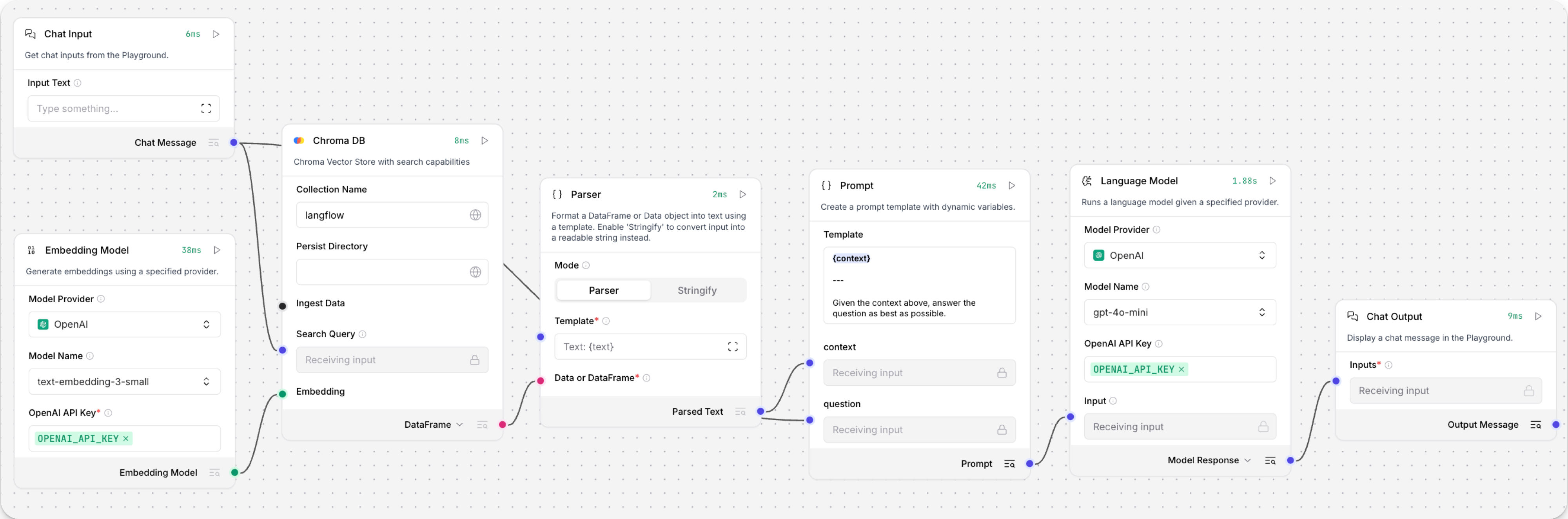
配置向量存储参数
大多数向量存储组件在流程中具有相同的实用性,但每个提供商可以提供不同的参数和功能。 检查组件的参数以了解更多关于它接受的输入以及如何配置它。
向量存储组件的许多输入参数在可视化编辑器中默认隐藏。 您可以通过每个组件标题菜单中的 Controls 切换参数。
有关特定提供商参数的详细信息,请参阅提供商的文档。
Astra DB
此组件实现了具有搜索功能的 Astra DB Serverless 向量存储。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| token | Astra DB Application Token | 访问 Astra DB 的身份验证令牌。 |
| environment | Environment | Astra DB API 端点的环境。例如,dev 或 prod。 |
| database_name | Database | Astra DB 实例的数据库名称。 |
| api_endpoint | Astra DB API Endpoint | Astra DB 实例的 API 端点。这取代数据库选择。 |
| collection_name | Collection | Astra DB 中存储向量的集合名称。 |
| keyspace | Keyspace | Astra DB 中用于集合的可选键空间。 |
| embedding_choice | Embedding Model or Astra Vectorize | 选择嵌入模型或使用 Astra vectorize。 |
| embedding_model | Embedding Model | 指定嵌入模型。Astra vectorize 集合不需要。 |
| number_of_results | Number of Search Results | 要返回的搜索结果数量。默认:4。 |
| search_type | Search Type | 要使用的搜索类型。选项包括 Similarity、Similarity with score threshold 和 MMR (Max Marginal Relevance)。 |
| search_score_threshold | Search Score Threshold | 使用 Similarity with score threshold 选项时搜索结果的最小相似性分数阈值。 |
| advanced_search_filter | Search Metadata Filter | 应用于搜索查询的可选过滤器字典。 |
| autodetect_collection | Autodetect Collection | 确定是否自动检测集合的布尔标志。 |
| content_field | Content Field | 用作向量存储文本内容字段的字段。 |
| deletion_field | Deletion Based On Field | 提供时,在加载新数据之前会删除目标集合中元数据字段值与输入元数据字段值匹配的文档。 |
| ignore_invalid_documents | Ignore Invalid Documents | 确定是否在运行时忽略无效文档的布尔标志。 |
| astradb_vectorstore_kwargs | AstraDBVectorStore Parameters | AstraDBVectorStore 的可选附加参数字典。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | Vector Store | 使用指定参数配置的 Astra DB 向量存储实例。 |
| search_results | Search Results | 相似性搜索的结果,作为 Data 对象列表。 |
生成嵌入
Astra DB 组件提供两种生成嵌入的方法。
-
嵌入模型:通过在 Langflow 中连接嵌入模型组件来使用您自己的嵌入模型。
-
Astra Vectorize:使用 Astra DB 的内置嵌入生成服务。创建新集合时,选择嵌入提供商和模型,包括 DataStax 托管的 NVIDIA 的
NV-Embed-QA模型。 有关更多信息,请参阅 Astra DB Serverless 文档。important使用 vectorize 时,创建集合时选择的嵌入模型以后无法更改。
有关使用带有嵌入模型的 Astra DB 组件的示例,请参阅 Vector Store RAG 模板。
混合搜索
Astra DB 组件通过 Astra DB Data API 包含 Astra DB 的混合搜索功能。
混合搜索执行向量相似性搜索和词汇搜索,比较两个搜索的结果,然后返回总体最相关的结果。
Chroma DB
此组件实现了具有搜索功能的 Chroma 向量存储。
Local DB
此组件实现了一个内存向量存储,用于存储和检索嵌入,无需外部数据库。适用于测试和原型制作。
Memory
此组件提供内存向量存储功能,用于临时存储和检索向量数据。